Week 10 [Oct 22]
Todo
Admin info to read:
Overview: Continue to enhance features. Make code RepoSense-compatible. Try doing a proper release.
Project Management:
- Continue to do deliberate project management using GitHub issue tracker, milestones, labels, etc. as you did in v1.2.
- 💡 We recommend that each PR also updates the relevant parts of documents and tests. That way, your documentation/testing work will not pile up towards the end.
- 💡 There is a way to get GitHub to auto-close the relevant issue when a PR is merged (example).
Ensure your code is
In previous semesters we asked students to annotate all their code using special @@author tags so that we can extract each student's code for grading. This semester, we are trying out a new tool called RepoSense that is
expected to reduce the need for such tagging, and also make it easier for you to see (and learn from) code written by others.
1. View the current status of code authorship data:
- The report generated by the tool is available at Code Dashboard (BETA). The feature that is most relevant to you is the Code Panel (shown on the right side of the screenshot above). It shows the code attributed to a given author. You are welcome to play around with the other features (they are still under development and will not be used for grading this semester).
- Click on your name to load the code attributed to you (based on Git blame/log data) onto the code panel on the right.
- If the code shown roughly matches the code you wrote, all is fine and there is nothing for you to do.
2. If the code does not match:
-
Here are the possible reasons for the code shown not to match the code you wrote:
- the git username in some of your commits does not match your GitHub username (perhaps you missed our instructions to set your Git username to match GitHub username earlier in the project, or GitHub did not honor your Git username for some reason)
- the actual authorship does not match the authorship determined by git blame/log e.g., another student touched your code after you wrote it, and Git log attributed the code to that student instead
-
In those cases,
- Install RepoSense (see the Getting Started section of the RepoSense User Guide)
- Use the two methods described in the RepoSense User Guide section Configuring a Repo to Provide Additional Data to RepoSense to provide additional data to the authorship analysis to make it more accurate.
- If you add a
config.jsonfile to your repo (as specified by one of the two methods),- Please use the template json file given in the module website so that your display name matches the name we expect it to be.
- If your commits have multiple author names, specify all of them e.g.,
"authorNames": ["theMyth", "theLegend", "theGary"] - Update the line
config.jsonin the.gitignorefile of your repo as/config.jsonso that it ignores theconfig.jsonproduced by the app but not the_reposense/config.json.
- If you add
@@authorannotations, please follow the guidelines below:
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
- After you are satisfied with the new results (i.e., results produced by running RepoSense locally), push the
config.jsonfile you added and/or the annotated code to your repo. We'll use that information the next time we run RepoSense (we run it at least once a week). - If you choose to annotate code, please annotate code chunks not smaller than a method. We do not grade code snippets smaller than a method.
- If you encounter any problem when doing the above or if you have questions, please post in the forum.
We recommend you ensure your code is RepoSense-compatible by v1.3
Product:
-
Do a
proper product release as described in the AB4 Developer Guide. You can name it something likev1.2.1. Ensure that the jar file works as expected by doing some manual testing. Reason: You are required to do a proper product release for v1.3. Doing a trial at this point will help you iron out any problems in advance. It may take additional effort to get the jar working especially if you use third party libraries or additional assets such as images.
Documentation:
- User Guide: Update where the document does not match the current product.
- Developer Guide: Similar to User Guide.
Demo:
- Optional. If you want feedback on your features, you can demo the feature and get feedback from the tutor.
Outcomes
SE
W10.1 Can explain SE principles
W10.1a Can explain the Law of Demeter
Supplmentary → Principles →
Law of Demeter
Law of Demeter (LoD):
- An object should have limited knowledge of another object.
- An object should only interact with objects that are closely related to it.
Also known as
- Don’t talk to strangers.
- Principle of least knowledge
More concretely, a method m of an object O should invoke only the methods of the following kinds of objects:
- The object
Oitself - Objects passed as parameters of
m - Objects created/instantiated in
m - Objects from the
direct association of O
The following code fragment violates LoD due to the reason: while b is a ‘friend’ of foo (because it receives it as a parameter), g is a ‘friend of a friend’
(which should be considered a ‘stranger’), and g.doSomething() is analogous to ‘talking to a stranger’.
void foo(Bar b) {
Goo g = b.getGoo();
g.doSomething();
}
LoD aims to reduce coupling by limiting the interaction to a closely related group of classes.
In the example above, foo is already coupled to Bar. Upholding LoD avoids foo being coupled to Goo as well.
An analogy for LoD can be drawn from Facebook. If Facebook followed LoD, you would not be allowed to see posts of friends of friends, unless they are your friends as well. If Jake is your friend and Adam is Jake’s friend, you should not be allowed to see Adam’s posts unless Adam is a friend of yours as well.
Explain the Law of Demeter using code examples. You are to make up your own code examples. Take Minesweeper as the basis for your code examples.
Let us take the Logic class as an example. Assume that it has the following operation.
setMinefield(Minefiled mf):void
Consider the following that can happen inside this operation.
mf.init();: this does not violate LoD since LoD allows calling operations of parameters received.mf.getCell(1,3).clear();: //this violates LoD becauseLogicis handlingCellobjects deep insideMinefield. Instead, it should bemf.clearCellAt(1,3);timer.start();: //this does not violate LoD becausetimerappears to be an internal component (i.e. a variable) ofLogicitself.Cell c = new Cell();c.init();: // this does not violate LoD becausecwas created inside the operation.
This violates Law of Demeter.
void foo(Bar b) {
Goo g = new Goo();
g.doSomething();
}
False
Explanation: The line g.doSomething() does not violate LoD because it is OK to invoke methods of objects created within a method.
Pick the odd one out.
- a. Law of Demeter.
- b. Don’t add people to a late project.
- c. Don’t talk to strangers.
- d. Principle of least knowledge.
- e. Coupling.
(b)
Explanation: Law of Demeter, which aims to reduce coupling, is also known as ‘Don’t talk to strangers’ and ‘Principle of least knowledge’.
Evidence:
Identify places where LoD is followed/violated in your project.
W10.1b Can explain SOLID Principles
Supplmentary → Principles →
SOLID Principles
The five OOP principles given below are known as SOLID Principles (an acronym made up of the first letter of each principle):
Supplmentary → Principles →
Single Responsibility Principle
Single Responsibility Principle (SRP): A class should have one, and only one, reason to change. -- Robert C. Martin
If a class has only one responsibility, it needs to change only when there is a change to that responsibility.
Consider a TextUi class that does parsing of the user commands as well as interacting with the user. That class needs to change when the formatting of the UI changes as well
as when the syntax of the user command changes. Hence, such a class does not follow the SRP.
- An explanation of the SRP from www.oodesign.com
- Another explanation (more detailed) by Patkos Csaba
- A book chapter on SRP - A book chapter on SRP, written by the father of the principle itself Robert C Martin.
Supplmentary → Principles →
Open-Closed Principle
While it is possible to isolate the functionalities of a software system into modules, there is no way to remove interaction between modules. When modules interact with each other, coupling naturally increases. Consequently, it is harder to localize any changes to the software system. The Open-Close Principle aims to alleviate this problem.
Open-Closed Principle (OCP): A module should be open for extension but closed for modification. That is, modules should be written so that they can be extended, without requiring them to be modified. -- proposed by Bertrand Meyer
In object-oriented programming, OCP can be achieved in various ways. This often requires separating the specification (i.e. interface) of a module from its implementation.
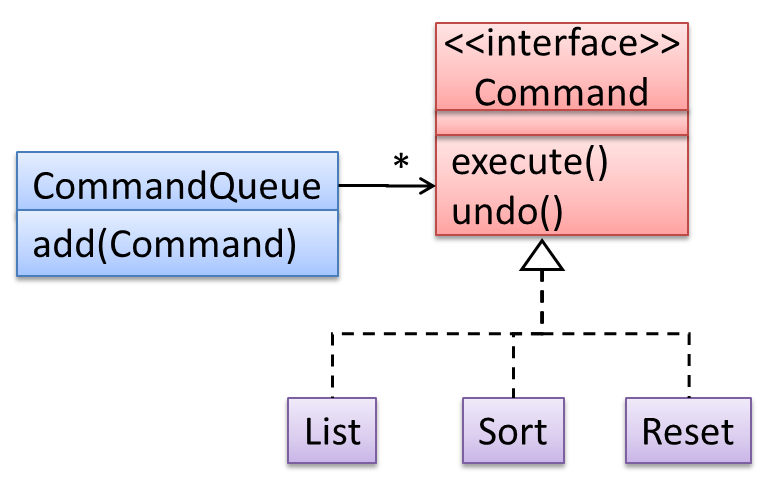
In the design given below, the behavior of the CommandQueue class can be altered by adding more concrete Command subclasses. For example, by including a Delete class alongside List, Sort, and Reset, the CommandQueue can now perform delete commands without modifying its code at all. That is, its behavior was extended without
having to modify its code. Hence, it was open to extensions, but closed to modification.
The behavior of a Java generic class can be altered by passing it a different class as a parameter. In the code below, the ArrayList class behaves as a container of Students in one instance and as a container of Admin objects in the other instance, without having to change its code. That is, the behavior of the ArrayList class is extended without modifying its
code.
ArrayList students = new ArrayList< Student >();
ArrayList admins = new ArrayList< Admin >();
Which of these is closest to the meaning of the open-closed principle?
(a)
Explanation: Please refer the handout for the definition of OCP.
Supplmentary → Principles →
Liskov Substitution Principle
Liskov Substitution Principle (LSP): Derived classes must be substitutable for their base classes. -- proposed by Barbara Liskov
LSP sounds same as
Paradigms → Object Oriented Programming → Inheritance →
Substitutability
Every instance of a subclass is an instance of the superclass, but not vice-versa. As a result, inheritance allows substitutability : the ability to substitute a child class object where a parent class object is expected.
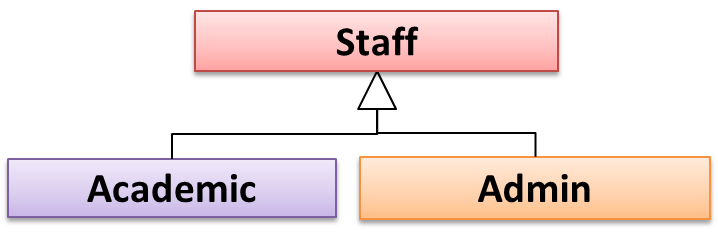
an Academic is an instance of a Staff, but a Staff is not necessarily an instance of an Academic. i.e. wherever an object
of the superclass is expected, it can be substituted by an object of any of its subclasses.
The following code is valid because an AcademicStaff object is substitutable as a Staff object.
Staff staff = new AcademicStaff (); // OK
But the following code is not valid because staff is declared as a Staff type and therefore its value may or may not be of type AcademicStaff, which is the type expected by variable academicStaff.
Staff staff;
...
AcademicStaff academicStaff = staff; // Not OK
Suppose the Payroll class depends on the adjustMySalary(int percent) method of the Staff class. Furthermore, the Staff class states
that the adjustMySalary method will work for all positive percent values. Both Admin and Academic classes override the adjustMySalary method.
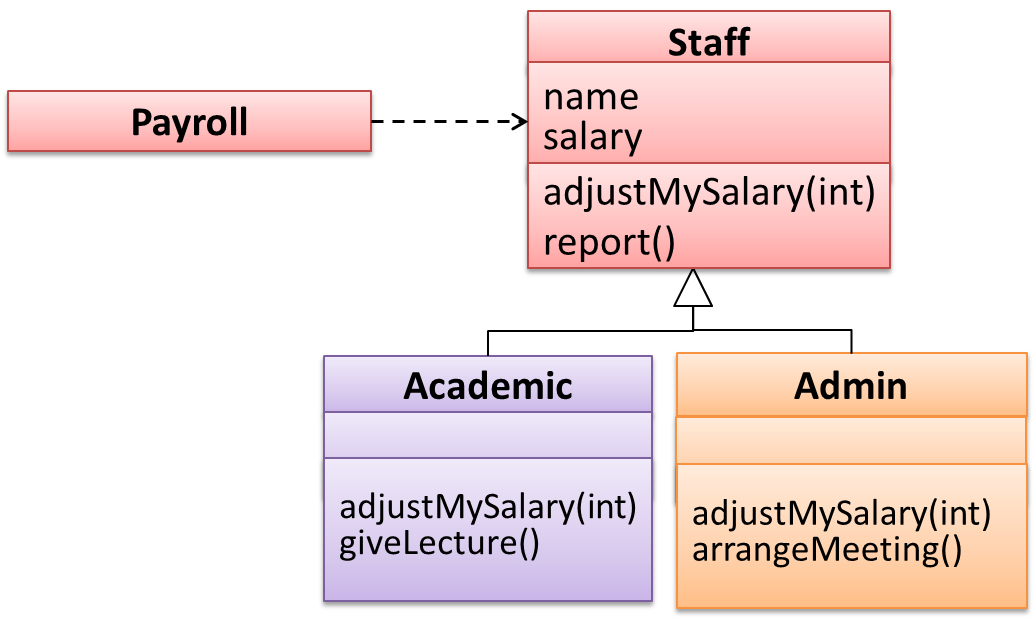
Now consider the following:
Admin#adjustMySalarymethod works for both negative and positive percent values.Academic#adjustMySalarymethod works for percent values1..100only.
In the above scenario,
Adminclass follows LSP because it fulfillsPayroll’s expectation ofStaffobjects (i.e. it works for all positive values). SubstitutingAdminobjects for Staff objects will not break thePayrollclass functionality.Academicclass violates LSP because it will not work for percent values over100as expected by thePayrollclass. SubstitutingAcademicobjects forStaffobjects can potentially break thePayrollclass functionality.
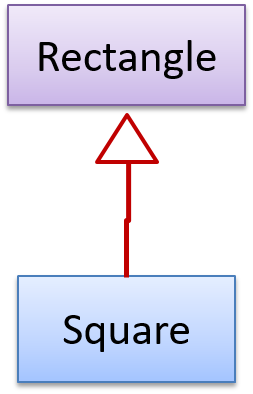
The Rectangle#resize() can take any integers for height and width. This contract is violated by the subclass Square#resize() because
it does not accept a height that is different from the width.
class Rectangle {
...
/** sets the size to given height and width*/
void resize(int height, int width){
...
}
}
class Square extends Rectangle {
@Override
void resize(int height, int width){
if (height != width) {
//error
}
}
}
Now consider the following method that is written to work with the Rectangle class.
void makeSameSize(Rectangle original, Rectangle toResize){
toResize.resize(original.getHeight(), original.getWidth());
}
This code will fail if it is called as maekSameSize(new Rectangle(12,8), new Square(4, 4)) That is, Square class is not substitutable for the Rectangle class.
If a subclass imposes more restrictive conditions than its parent class, it violates Liskov Substitution Principle.
True.
Explanation: If the subclass is more restrictive than the parent class, code that worked with the parent class may not work with the child class. Hence, the substitutability does not exist and LSP has been violated.
Supplmentary → Principles →
Interface Segregation Principle
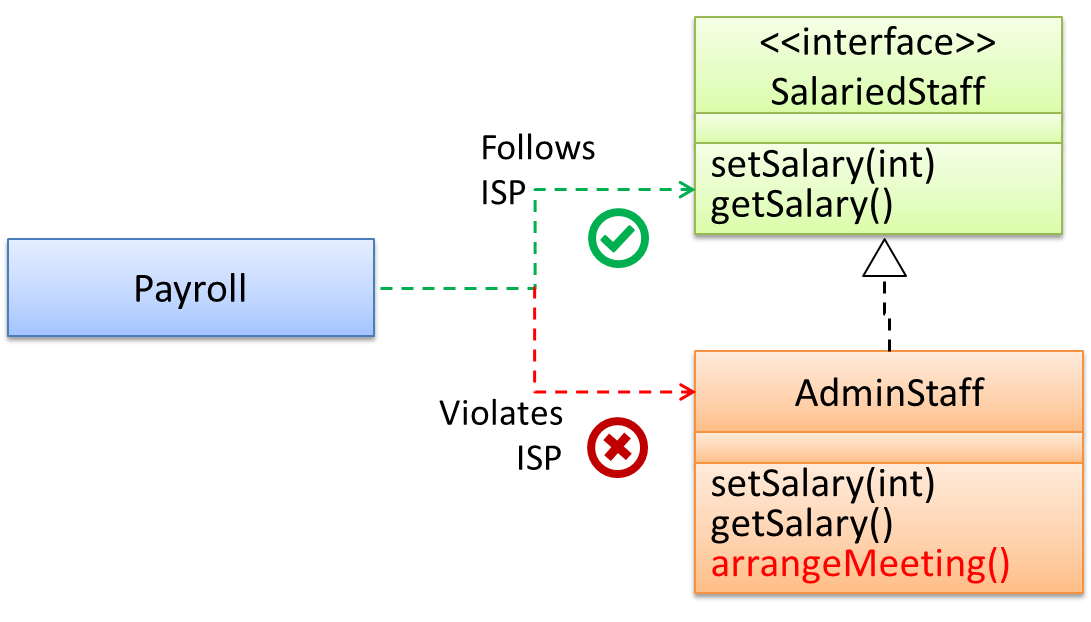
Interface Segregation Principle (ISP): No client should be forced to depend on methods it does not use.
The Payroll class should not depend on the AdminStaff class because it does not use the arrangeMeeting() method. Instead, it should depend on the
SalariedStaff interface.
public class Payroll {
//...
private void adjustSalaries(AdminStaff adminStaff){ //violates ISP
//...
}
}
public class Payroll {
//...
private void adjustSalaries(SalariedStaff staff){ //does not violate ISP
//...
}
}
Supplmentary → Principles →
Dependency Inversion Principle
The Dependency Inversion Principle states that,
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
Example:
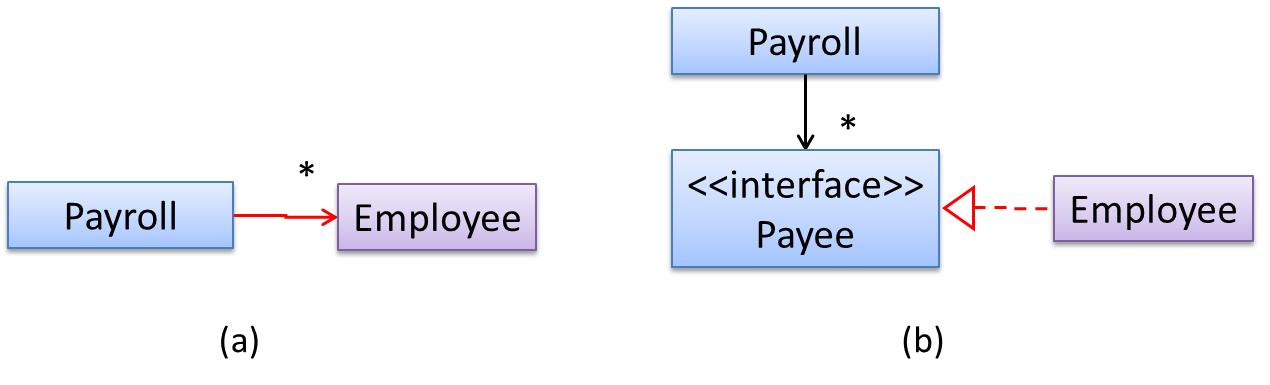
In design (a), the higher level class Payroll depends on the lower level class Employee, a violation of DIP. In design (b), both Payroll and Employee depends on the
Payee interface (note that inheritance is a dependency).
Design (b) is more flexible (and less coupled) because now the Payroll class need not change when the Employee class changes.
Which of these statements is true about the Dependency Inversion Principle.
- a. It can complicate the design/implementation by introducing extra abstractions, but it has some benefits.
- b. It is often used during testing, to replace dependencies with mocks.
- c. It reduces dependencies in a design.
- d. It advocates making higher level classes to depend on lower level classes.
- a. It can complicate the design/implementation by introducing extra abstractions, but it has some benefits.
- b. It is often used during testing, to replace dependencies with mocks.
- c. It reduces dependencies in a design.
- d. It advocates making higher level classes to depend on lower level classes.
Explanation: Replacing dependencies with mocks is Dependency Injection, not DIP. DIP does not reduce dependencies, rather, it changes the direction of dependencies. Yes, it can introduce extra abstractions but often the benefit can outweigh the extra complications.
W10.1c Can explain YAGNI principle
Supplmentary → Principles →
YAGNI Principle
YAGNI (You Aren't Gonna Need It!) Principle: Do not add code simply because ‘you might need it in the future’.
The principle says that some capability we presume our software needs in the future should not be built now because the chances are "you aren't gonna need it". The rationale is that we do not have perfect information about the future and therefore some of the extra work we do to fulfill a potential future need might go to waste when some of our predictions fail to materialize.
- Yagni -- A detailed article explaining YAGNI, written by Martin Fowler.
W10.1d Can explain DRY principle
Supplmentary → Principles →
DRY Principle
DRY (Don't Repeat Yourself) Principle: Every piece of knowledge must have a single, unambiguous, authoritative representation within a system The Pragmatic Programmer, by Andy Hunt and Dave Thomas
This principle guards against duplication of information.
The functionality implemented twice is a violation of the DRY principle even if the two implementations are different.
The value a system-wide timeout being defined in multiple places is a violation of DRY.
W10.1e Can explain Brooks' law
Supplmentary → Principles →
Brooks' Law
Brooks' Law: Adding people to a late project will make it later. -- Fred Brooks (author of The Mythical Man-Month)
Explanation: The additional communication overhead will outweigh the benefit of adding extra manpower, especially if done near to a deadline.
Do the Brook’s Law apply to a school project? Justify.
Yes. Adding a new student to a project team can result in a slow-down of the project for a short period. This is because the new member needs time to learn the project and existing members will have to spend time helping the new guy get up to speed. If the project is already behind schedule and near a deadline, this could delay the delivery even further.
Which one of these (all attributed to Fred Brooks, the author of the famous SE book The Mythical Man-Month), is called the Brook’s law?
- a. All programmers are optimists.
- b. Good judgement comes from experience, and experience comes from bad judgement.
- c. The bearing of a child takes nine months, no matter how many women are assigned.
- d. Adding more manpower to an already late project makes it even later.
(d)
Requirements
W10.2 Can use activity diagrams
Basic notations
W10.2a Can use activity diagrams
Design → Modelling → Modelling Behaviors
Activity Diagrams
Software projects often involve workflows. Workflows define the
Some examples in which a certain workflow is relevant to software project:
A software that automates the work of an insurance company needs to take into account the workflow of processing an insurance claim.
The algorithm of a price of code represents the workflow (i.e. the execution flow) of the code.
Understanding such workflows is important for the success of the software project.
Unified Modeling Language (UML) is a graphical notation to describe various aspects of a software system. UML is the brainchild of three software modeling specialists James Rumbaugh, Grady Booch and Ivar Jacobson (also known as the Three Amigos). Each of them has developed their own notation for modeling software systems before joining force to create a unified modeling language (hence, the term ‘Unified’ in UML). UML is currently the de facto modeling notation used in the software industry.
An example activity diagram [source:wikipeida]:

The most basic activity diagram is simply a linear sequence of actions.
Some workflows have alternate paths where only one of the alternate paths is taken based on some condition.
In some workflows, multiple paths happen in parallel.
Which of these sequence of actions is not allowed by the given activity diagram?
- i. start a b c d end
- ii. start a b c d e f g c d end
- iii. start a b c d e g f c d end
- iv. start a b c d g c d end
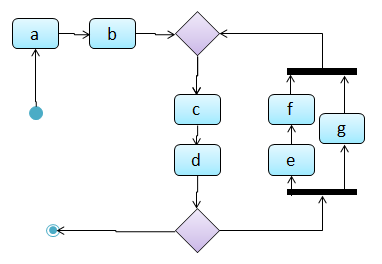
(iv)
Explanation: -e-f- and -g- are parallel paths. Both paths should complete before the execution reaches c again.
Evidence:
Use activity diagram to model workflows in the project.
Intermediate notations
W10.2b Can use rakes in activity diagrams
Tools → UML → Activity Diagrams →
Rakes
The rake notation is used to indicate that a part of the activity is given as a separate diagram.
Here is the AD for a game of ‘Snakes and Ladders’.
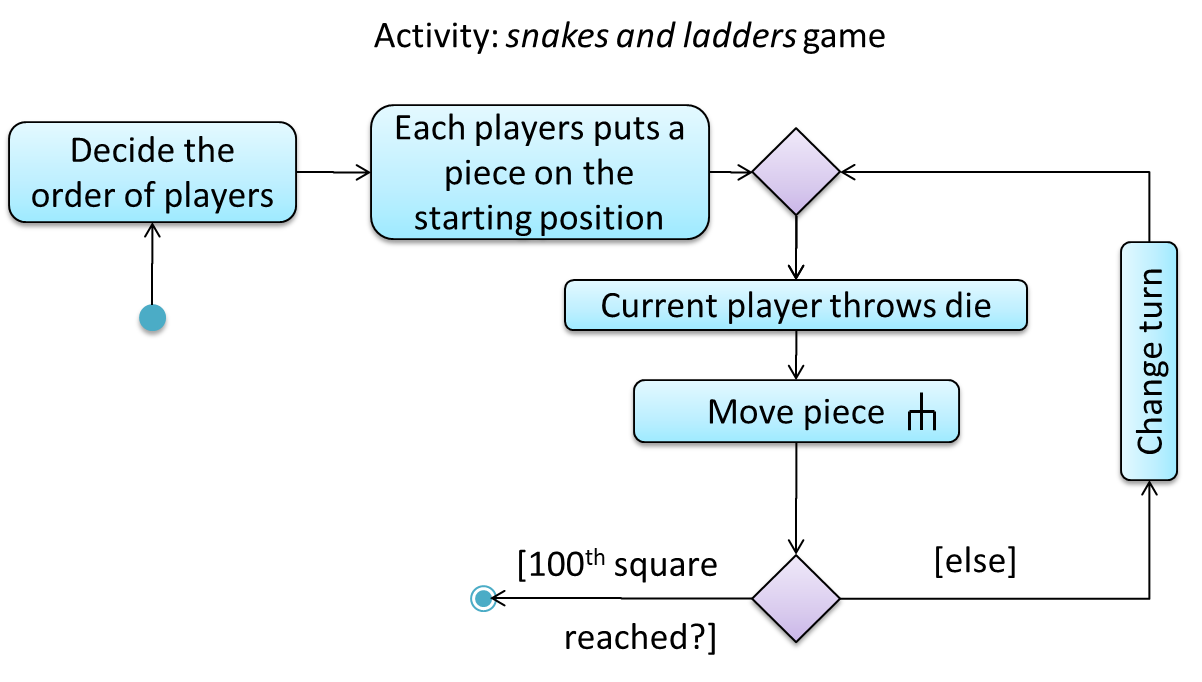
The rake symbol (in the Move piece action above) is used to show that the action is described in another subsidiary activity diagram elsewhere. That diagram is given below.
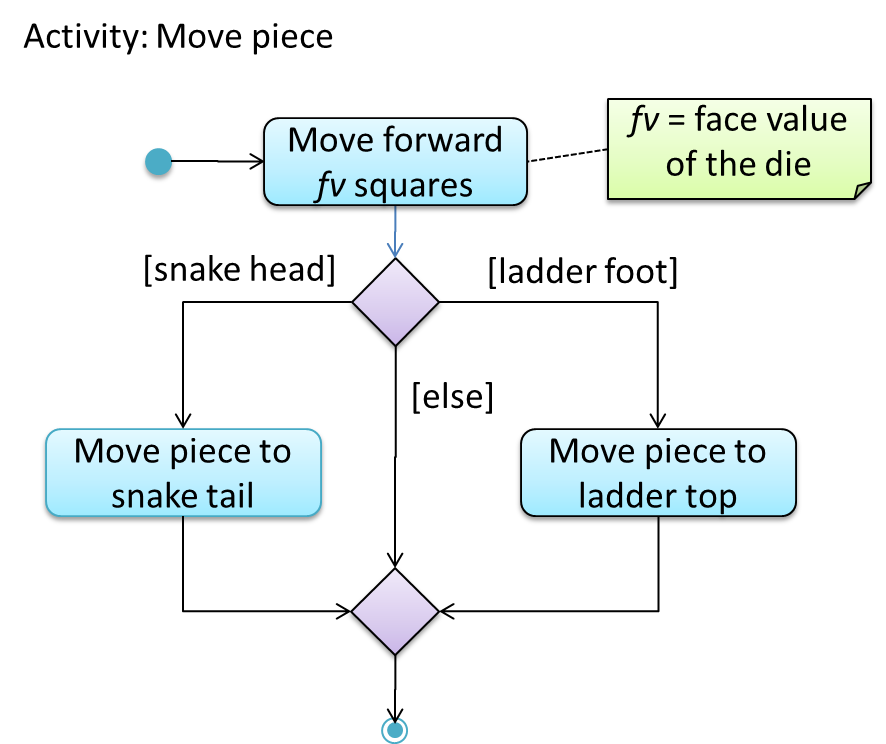
W10.2c Can explain swimlanes in activity diagrams
Tools → UML → Activity Diagrams →
Swimlanes
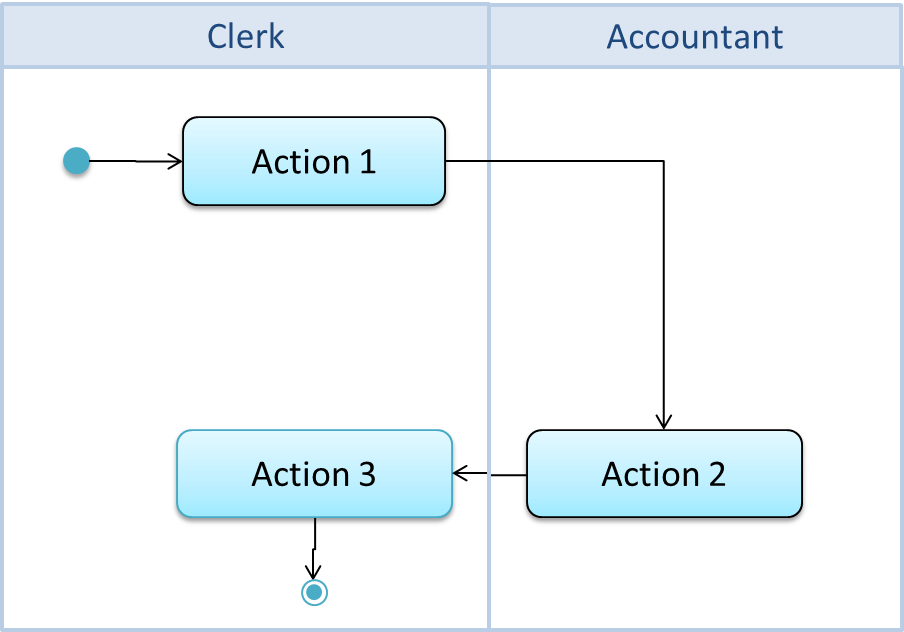
It is possible to partition an activity diagram to show who is doing which action. Such partitioned activity diagrams are sometime called swimlane diagrams.
A simple example of a swimlane diagram:
Design
W10.3 Can use some basic design patterns
Introduction
W10.3a Can explain design patterns
Design → Design Patterns → Introduction →
What
Design Pattern : An elegant reusable solution to a commonly recurring problem within a given context in software design.
In software development, there are certain problems that recur in a certain context.
Some examples of recurring design problems:
| Design Context | Recurring Problem |
|---|---|
| Assembling a system that makes use of other existing systems implemented using different technologies | What is the best architecture? |
| UI needs to be updated when the data in application backend changes | How to initiate an update to the UI when data changes without coupling the backend to the UI? |
After repeated attempts at solving such problems, better solutions are discovered and refined over time. These solutions are known as design patterns, **a term popularized by the seminal book Design Patterns: Elements of Reusable Object-Oriented Software by the so-called "Gang of Four"** (GoF) book written by Eric Gamma, Richard Helm, Ralph Johnson,and John Vlissides
Which one of these describes the ‘software design patterns’ concept best?
(b)
W10.3b Can explain design patterns format
Design → Design Patterns → Introduction →
Format
The common format to describe a pattern consists of the following components:
- Context: The situation or scenario where the design problem is encountered.
- Problem: The main difficulty to be resolved.
- Solution: The core of the solution. It is important to note that the solution presented only includes the most general details, which may need further refinement for a specific context.
- Anti-patterns (optional): Commonly used solutions, which are usually incorrect and/or inferior to the Design Pattern.
- Consequences (optional): Identifying the pros and cons of applying the pattern.
- Other useful information (optional): Code examples, known uses, other related patterns, etc.
When we describe a pattern, we must also specify anti-patterns.
False.
Explanation: Anti-patterns are related to patterns, but they are not a ‘must have’ component of a pattern description.
Singleton pattern
W10.3c Can explain the Singleton design pattern
Design → Design Patterns → Singleton →
What
Context
A certain classes should have no more than just one instance (e.g. the main controller class of the system). These single instances are commonly known as singletons.
Problem
A normal class can be instantiated multiple times by invoking the constructor.
Solution
Make the constructor of the singleton class private, because a public constructor will allow others to instantiate the class at will. Provide a public class-level
method to access the single instance.
Example:

We use the Singleton pattern when
(c)
Evidence:
Identify where in the project Singleton pattern can be used.
W10.3d Can apply the Singleton design pattern
Design → Design Patterns → Singleton →
Implementation
Here is the typical implementation of how the Singleton pattern is applied to a class:
class Logic {
private static Logic theOne = null;
private Logic() {
...
}
public static Logic getInstance() {
if (theOne == null) {
theOne = new Logic();
}
return theOne;
}
}
Notes:
- The constructor is
private, which prevents instantiation from outside the class. - The single instance of the singleton class is maintained by a
privateclass-level variable. - Access to this object is provided by a
publicclass-level operationgetInstance()which instantiates a single copy of the singleton class when it is executed for the first time. Subsequent calls to this operation return the single instance of the class.
If Logic was not a Singleton class, an object is created like this:
Logic m = new Logic();
But now, the Logic object needs to be accessed like this:
Logic m = Logic.getInstance();
Evidence:
Identify where in the project Singleton pattern has been used. Apply singleton pattern somewhere (in a toy example or in a project)
W10.3e Can decide when to apply Singleton design pattern
Design → Design Patterns → Singleton →
Evaluation
Pros:
- easy to apply
- effective in achieving its goal with minimal extra work
- provides an easy way to access the singleton object from anywhere in the code base
Cons:
- The singleton object acts like a global variable that increases coupling across the code base.
- In testing, it is difficult to replace Singleton objects with stubs (static methods cannot be overridden)
- In testing, singleton objects carry data from one test to another even when we want each test to be independent of the others.
Given there are some significant cons, it is recommended that you apply the Singleton pattern when, in addition to requiring only one instance of a class, there is a risk of creating multiple objects by mistake, and creating such multiple objects has real negative consequences.
Evidence:
Identify places in the project where only a single object of a class is needed but there is no need to apply the Singleton pattern.
Facade pattern
W10.3f Can explain the Facade design pattern
Design → Design Patterns → Facade Pattern →
What
Context
Components need to access functionality deep inside other components.
The UI component of a Library system might want to access functionality of the Book class contained inside the Logic component.
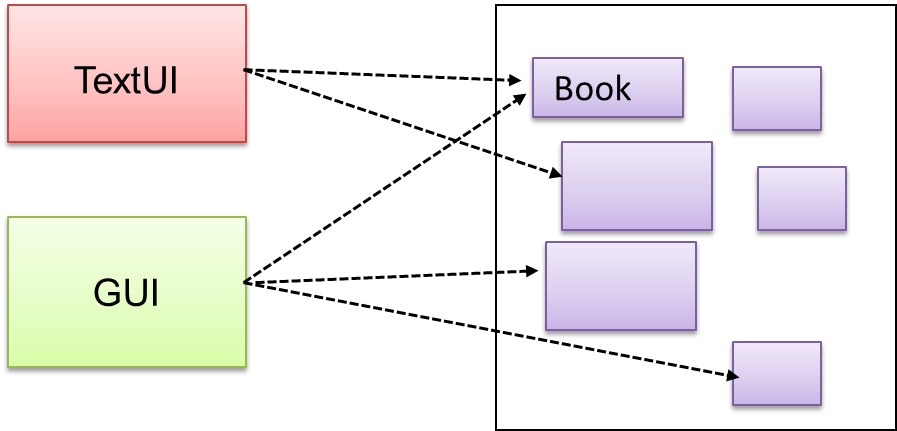
Problem
Access to the component should be allowed without exposing its internal details. e.g. the UI component should access the functionality of the Logic component without knowing that it contained a Book class within it.
Solution
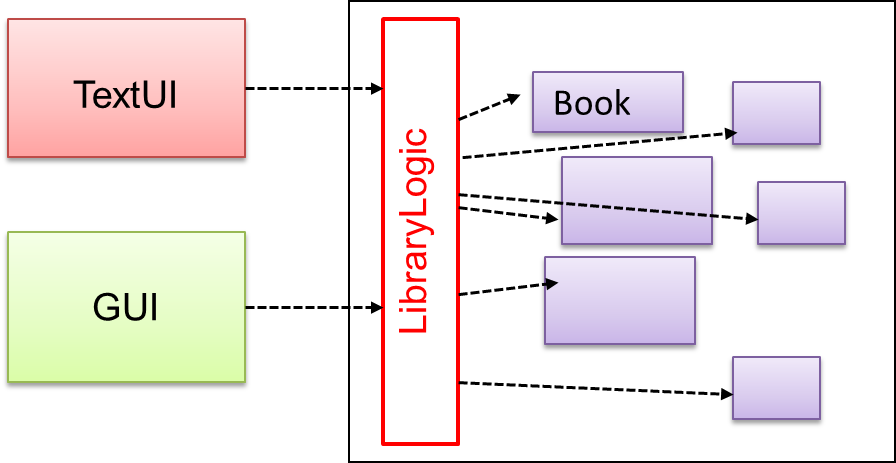
Include a
The following class diagram applies the Façade pattern to the Library System example. The LibraryLogic class is the Facade class.
Does the design below likely to use the Facade pattern?
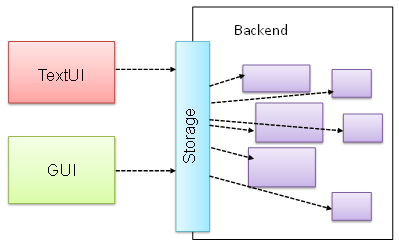
True.
Facade is clearly visible (Storage is the << Facade >> class).
Evidence:
Discuss the current/potential applications of the pattern in your project.
Command pattern
W10.3g Can explain the Command design pattern
Design → Design Patterns → Command Pattern →
What
Context
A system is required to execute a number of commands, each doing a different task. For example, a system might have to support Sort, List, Reset commands.
Problem
It is preferable that some part of the code executes these commands without having to know each command type. e.g., there can be a CommandQueue object that is responsible for queuing commands and executing them without knowledge of what each command does.
Solution
The essential element of this pattern is to have a general << Command >> object that can be passed around, stored, executed, etc without knowing the type of command (i.e. via polymorphism).
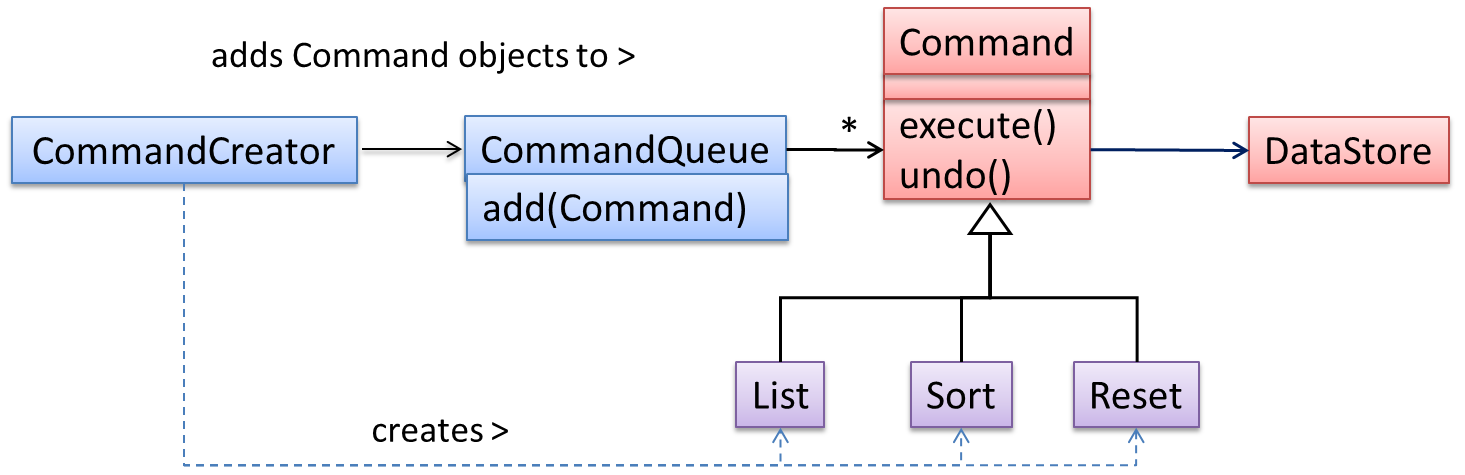
Let us examine an example application of the pattern first:
In the example solution below, the CommandCreator creates List, Sort, and Reset Command objects and adds them to the CommandQueue object. The CommandQueue object treats them all as Command objects and performs the execute/undo operation on each of them without knowledge of the specific Command type. When executed,
each Command object will access the DataStore object to carry out its task. The Command class can also be an abstract class or an interface.
The general form of the solution is as follows.
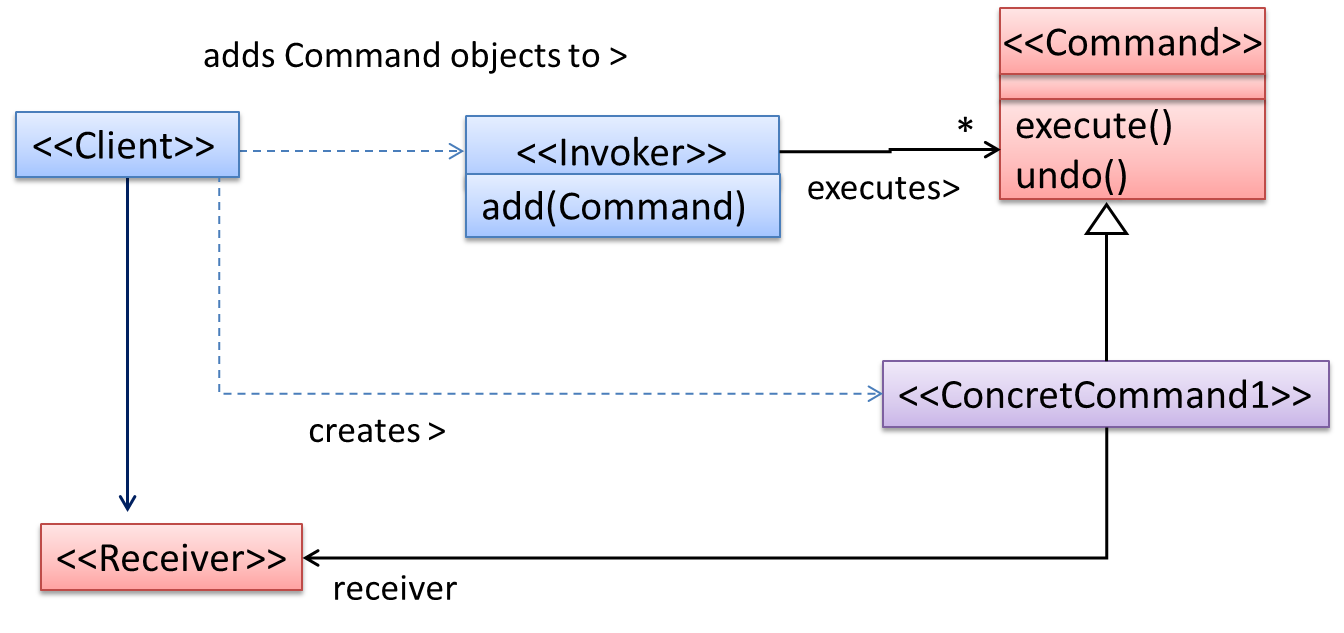
The << Client >> creates a << ConcreteCommand >> object, and passes it to the << Invoker >>. The << Invoker >> object treats all
commands as a general << Command >> type. << Invoker >> issues a request by calling execute() on the command. If a command is undoable, << ConcreteCommand >> will store the state for undoing the command prior to invoking execute(). In addition, the << ConcreteCommand >> object may have to be linked to any << Receiver >> of the command (
<< Invoker >>. Note that an application of the command pattern does not have to follow the structure given above.
Evidence:
Discuss the current/potential applications of the pattern in your project.
Implementation
W10.4 Can get reuse benefits from frameworks, libraries, and platforms
Reuse
W10.4a Can explain software reuse
Implementation → Reuse → Introduction →
What
Reuse is a major theme in software engineering practices. By reusing tried-and-tested components, the robustness of a new software system can be enhanced while reducing the manpower and time requirement. Reusable components come in many forms; it can be reusing a piece of code, a subsystem, or a whole software.
W10.4b Can explain the costs and benefits of reuse
Implementation → Reuse → Introduction →
When
While you may be tempted to use many libraries/frameworks/platform that seem to crop up on a regular basis and promise to bring great benefits, note that there are costs associated with reuse. Here are some:
- The reused code may be an overkill (think using a sledgehammer to crack a nut) increasing the size of, or/and degrading the performance of, your software.
- The reused software may not be mature/stable enough to be used in an important product. That means the software can change drastically and rapidly, possibly in ways that break your software.
- Non-mature software has the risk of dying off as fast as they emerged, leaving you with a dependency that is no longer maintained.
- The license of the reused software (or its dependencies) restrict how you can use/develop your software.
- The reused software might have bugs, missing features, or security vulnerabilities that are important to your product but not so important to the maintainers of that software, which means those flaws will not get fixed as fast as you need them to.
- Malicious code can sneak into your product via compromised dependencies.
One of your teammates is proposing to use a recently-released “cool” UI framework for your class project. List the pros and cons of this idea.
Pros
- The potential to create a much better product by reusing the framework.
- Learning a new framework is good for the future job prospects.
Cons
- Learning curve may be steep.
- May not be stable (it was recently released).
- May not allow us to do exactly what we want. While frameworks allow customization, such customization can be limited.
- Performance penalties.
- Might interfere with learning objectives of the module.
Note that having more cons does not mean we should not use this framework. Further investigation is required before we can make a final decision.
Evidence:
Have reused software. Can explain general costs and benefits of the code you have reused.
Libraries
W10.4c Can explain libraries
Implementation → Reuse → Libraries →
What
A library is a collection of modular code that is general and can be used by other programs.
Java classes you get with the JDK (such as String, ArrayList, HashMap, etc.) are library classes that are provided in the default Java distribution.
Natty is a Java library that can be used for parsing strings that represent dates e.g. The 31st of April in the year 2008
built-in modules you get with Python (such as csv, random, sys, etc.) are libraries that are provided in the default Python distribution. Classes such as
list, str, dict are built-in library classes that you get with Python.
Colorama is a Python library that can be used for colorizing text in a CLI.
Evidence:
Identify libraries used (or potentially usable) in your project.
W10.4d Can make use of a library
Implementation → Reuse → Libraries →
How
These are the typical steps required to use a library.
- Read the documentation to confirm that its functionality fits your needs
- Check the license to confirm that it allows reuse in the way you plan to reuse it. For example, some libraries might allow non-commercial use only.
- Download the library and make it accessible to your project. Alternatively, you can configure your
dependency management tool to do it for you. - Call the library API from your code where you need to use the library functionality.
Evidence:
Have used libraries (or reused code from elsewhere) in your project.
Frameworks
W10.4e Can explain frameworks
Implementation → Reuse → Frameworks →
What
The overall structure and execution flow of a specific category of software systems can be very similar. The similarity is an opportunity to reuse at a high scale.
Running example:
IDEs for different programming languages are similar in how they support editing code, organizing project files, debugging, etc.
A software framework is a reusable implementation of a software (or part thereof) providing generic functionality that can be selectively customized to produce a specific application.
Running example:
Eclipse is an IDE framework that can be used to create IDEs for different programming languages.
Some frameworks provide a complete implementation of a default behavior which makes them immediately usable.
Running example:
Eclipse is a fully functional Java IDE out-of-the-box.
A framework facilitates the adaptation and customization of some desired functionality.
Running example:
Eclipse plugin system can be used to create an IDE for different programming languages while reusing most of the existing IDE features of Eclipse. E.g. https://marketplace.eclipse.org/content/pydev-python-ide-eclipse
Some frameworks cover only a specific components or an aspect.
JavaFx a framework for creating Java GUIs. TkInter is a GUI framework for Python.
More examples of frameworks
- Frameworks for Web-based applications: Drupal(PHP), Django(Python), Ruby on Rails (Ruby), Spring (Java)
- Frameworks for testing: JUnit (Java), unittest (Python), Jest (Java Script)
Evidence:
Identify frameworks used (or potentially usable) in your project.
W10.4f Can differentiate between frameworks and libraries
Implementation → Reuse → Frameworks →
Frameworks vs Libraries
Although both frameworks and libraries are reuse mechanisms, there are notable differences:
-
Libraries are meant to be used ‘as is’ while frameworks are meant to be customized/extended. e.g., writing plugins for Eclipse so that it can be used as an IDE for different languages (C++, PHP, etc.), adding modules and themes to Drupal, and adding test cases to JUnit.
-
Your code calls the library code while the framework code calls your code. Frameworks use a technique called inversion of control, aka the “Hollywood principle” (i.e. don’t call us, we’ll call you!). That is, you write code that will be called by the framework, e.g. writing test methods that will be called by the JUnit framework. In the case of libraries, your code calls libraries.
Choose correct statements about software frameworks.
- a. They follow the hollywood principle, otherwise known as ‘inversion of control’
- b. They come with full or partial implementation.
- c. They are more concrete than patterns or principles.
- d. They are often configurable.
- e. They are reuse mechanisms.
- f. They are similar to reusable libraries but bigger.
(a)(b)(c)(d)(e)(f)
Explanation: While both libraries and frameworks are reuse mechanisms, and both more concrete than principles and patterns, libraries differ from frameworks in some key ways. One of them is the ‘inversion of control’ used by frameworks but not libraries. Furthermore, frameworks do not have to be bigger than libraries all the time.
Which one of these are frameworks ?
(a)(b)(c)(d)
Explanation: These are frameworks.
Evidence:
Explain the difference between libraries and frameworks using frameworks and libraries in your project as examples.
Platforms
W10.4g Can explain platforms
Implementation → Reuse → Platforms →
What
A platform provides a runtime environment for applications. A platform is often bundled with various libraries, tools, frameworks, and technologies in addition to a runtime environment but the defining characteristic of a software platform is the presence of a runtime environment.
Technically, an operating system can be called a platform. For example, Windows PC is a platform for desktop applications while iOS is a platform for mobile apps.
Two well-known examples of platforms are JavaEE and .NET, both of which sit above Operating systems layer, and are used to develop
- JavaEE (Java Enterprise Edition) is both a framework and a platform for writing enterprise applications. The runtime used by the JavaEE applications is the JVM (Java Virtual Machine) that can run on different Operating Systems.
- .NET is a similar platform and a framework. Its runtime is called CLR (Common Language Runtime) and usually used on Windows machines.
Enterprise Application: ‘enterprise applications’ means software applications used at organizations level and therefore has to meet much higher demands (such as in scalability, security, performance, and robustness) than software meant for individual use.
Evidence:
Identify platforms used (or potentially usable) in your project.
Quality Assurance
W10.5 Can explain test case design
W10.5a Can explain the need for deliberate test case design
Quality Assurance → Test Case Design → Introduction →
What
Except for trivial
Consider the test cases for adding a string object to a
- Add an item to an empty collection.
- Add an item when there is one item in the collection.
- Add an item when there are 2, 3, .... n items in the collection.
- Add an item that has an English, a French, a Spanish, ... word.
- Add an item that is the same as an existing item.
- Add an item immediately after adding another item.
- Add an item immediately after system startup.
- ...
Exhaustive testing of this operation can take many more test cases.
Program testing can be used to show the presence of bugs, but never to show their absence!
--Edsger Dijkstra
Every test case adds to the cost of testing. In some systems, a single test case can cost thousands of dollars e.g. on-field testing of flight-control software. Therefore, test cases need to be designed to make the best use of testing resources. In particular:
-
Testing should be effective i.e., it finds a high percentage of existing bugs e.g., a set of test cases that finds 60 defects is more effective than a set that finds only 30 defects in the same system.
-
Testing should be efficient i.e., it has a high rate of success (bugs found/test cases) a set of 20 test cases that finds 8 defects is more efficient than another set of 40 test cases that finds the same 8 defects.
For testing to be
Given below is the sample output from a text-based program TriangleDetector ithat determines whether the three input numbers make up the three sides of a valid triangle. List test cases you would use to test
this software. Two sample test cases are given below.
C:\> java TriangleDetector
Enter side 1: 34
Enter side 2: 34
Enter side 3: 32
Can this be a triangle?: Yes
Enter side 1:
Sample test cases,
34,34,34: Yes
0, any valid, any valid: No
In addition to obvious test cases such as
- sum of two sides == third,
- sum of two sides < third ...
We may also devise some interesting test cases such as the ones depicted below.
Note that their applicability depends on the context in which the software is operating.
- Non-integer number, negative numbers,
0, numbers formatted differently (e.g.13F), very large numbers (e.g.MAX_INT), numbers with many decimal places, empty string, ... - Check many triangles one after the other (will the system run out of memory?)
- Backspace, tab, CTRL+C , …
- Introduce a long delay between entering data (will the program be affected by, say the screensaver?), minimize and restore window during the operation, hibernate the system in the middle of a calculation, start with invalid inputs (the system may perform error handling differently for the very first test case), …
- Test on different locale.
The main point to note is how difficult it is to test exhaustively, even on a trivial system.
Explain the why exhaustive testing is not practical using the example of testing newGame() operation in the Logic class of a Minesweeper game.
Consider this sequence of test cases:
- Test case 1. Start Minesweeper. Activate
newGame()and see if it works. - Test case 2. Start Minesweeper. Activate
newGame(). ActivatenewGame()again and see if it works. - Test case 3. Start Minesweeper. Activate
newGame()three times consecutively and see if it works. - …
- Test case 267. Start Minesweeper. Activate
newGame()267 times consecutively and see if it works.
Well, you get the idea. Exhaustive testing of newGame() is not practical.
Improving efficiency and effectiveness of test case design can,
- a. improve the quality of the SUT.
- b. save money.
- c. save time spent on test execution.
- d. save effort on writing and maintaining tests.
- e. minimize redundant test cases.
- f. forces us to understand the SUT better.
(a)(b)(c)(d)(e)(f)
Evidence:
Explain why testing needs to be E&E, using examples from your project.
W10.5b Can explain exploratory testing and scripted testing
Quality Assurance → Testing → Exploratory and Scripted Testing →
What
Here are two alternative approaches to testing a software: Scripted testing and Exploratory testing
-
Scripted testing: First write a set of test cases based on the expected behavior of the SUT, and then perform testing based on that set of test cases.
-
Exploratory testing: Devise test cases on-the-fly, creating new test cases based on the results of the past test cases.
Exploratory testing is ‘the simultaneous learning, test design, and test execution’
Here is an example thought process behind a segment of an exploratory testing session:
“Hmm... looks like feature x is broken. This usually means feature n and k could be broken too; we need to look at them soon. But before that, let us give a good test run to feature y because users can still use the product if feature y works, even if x doesn’t work. Now, if feature y doesn’t work 100%, we have a major problem and this has to be made known to the development team sooner rather than later...”
💡 Exploratory testing is also known as reactive testing, error guessing technique, attack-based testing, and bug hunting.
Exploratory Testing Explained, an online article by James Bach -- James Bach is an industry thought leader in software testing).
Scripted testing requires tests to be written in a scripting language; Manual testing is called exploratory testing.
A) False
Explanation: “Scripted” means test cases are predetermined. They need not be an executable script. However, exploratory testing is usually manual.
Which testing technique is better?
(e)
Explain the concept of exploratory testing using Minesweeper as an example.
When we test the Minesweeper by simply playing it in various ways, especially trying out those that are likely to be buggy, that would be exploratory testing.
Evidence:
Explain exploratory and scripted testing in the context of your project.
W10.5c Can explain the choice between exploratory testing and scripted testing
Quality Assurance → Testing → Exploratory and Scripted Testing →
When
Which approach is better – scripted or exploratory? A mix is better.
The success of exploratory testing depends on the tester’s prior experience and intuition. Exploratory testing should be done by experienced testers, using a clear strategy/plan/framework. Ad-hoc exploratory testing by unskilled or inexperienced testers without a clear strategy is not recommended for real-world non-trivial systems. While exploratory testing may allow us to detect some problems in a relatively short time, it is not prudent to use exploratory testing as the sole means of testing a critical system.
Scripted testing is more systematic, and hence, likely to discover more bugs given sufficient time, while exploratory testing would aid in quick error discovery, especially if the tester has a lot of experience in testing similar systems.
In some contexts, you will achieve your testing mission better through a more scripted approach; in other contexts, your mission will benefit more from the ability to create and improve tests as you execute them. I find that most situations benefit from a mix of scripted and exploratory approaches. --
[source: bach-et-explained]
Exploratory Testing Explained, an online article by James Bach -- James Bach is an industry thought leader in software testing).
Scripted testing is better than exploratory testing.
B) False
Explanation: Each has pros and cons. Relying on only one is not recommended. A combination is better.
W10.5d Can explain positive and negative test cases
Quality Assurance → Test Case Design → Introduction →
Positive vs Negative Test Cases
A positive test case is when the test is designed to produce an expected/valid behavior. A negative test case is designed to produce a behavior that indicates an invalid/unexpected situation, such as an error message.
Consider testing of the method print(Integer i) which prints the value of i.
- A positive test case:
i == new Integer(50) - A negative test case:
i == null;
Evidence:
Give examples of positive and negative test cases from your project.
W10.5e Can explain black box and glass box test case design
Quality Assurance → Test Case Design → Introduction →
Black Box vs Glass Box
Test case design can be of three types, based on how much of SUT internal details are considered when designing test cases:
-
Black-box (aka specification-based or responsibility-based) approach: test cases are designed exclusively based on the SUT’s specified external behavior.
-
White-box (aka glass-box or structured or implementation-based) approach: test cases are designed based on what is known about the SUT’s implementation, i.e. the code.
-
Gray-box approach: test case design uses some important information about the implementation. For example, if the implementation of a sort operation uses different algorithms to sort lists shorter than 1000 items and lists longer than 1000 items, more meaningful test cases can then be added to verify the correctness of both algorithms.
Note: these videos are from the Udacity course Software Development Process by Georgia Tech
Evidence:
Explain black/white/grey box testing using examples from your project.
W10.5f Can explain test case design for use case based testing
Quality Assurance → Test Case Design →
Testing Based on Use Cases
Use cases can be used for system testing and acceptance testing. For example, the main success scenario can be one test case while each variation (due to extensions) can form another test case. However, note that
use cases do not specify the exact data entered into the system. Instead, it might say something like user enters his personal data into the system. Therefore, the tester has to choose data by considering equivalence
partitions and boundary values. The combinations of these could result in one use case producing many test cases.
To increase
Every test case adds to the cost of testing. In some systems, a single test case can cost thousands of dollars e.g. on-field testing of flight-control software. Therefore, test cases need to be designed to make the best use of testing resources. In particular:
-
Testing should be effective i.e., it finds a high percentage of existing bugs e.g., a set of test cases that finds 60 defects is more effective than a set that finds only 30 defects in the same system.
-
Testing should be efficient i.e., it has a high rate of success (bugs found/test cases) a set of 20 test cases that finds 8 defects is more efficient than another set of 40 test cases that finds the same 8 defects.
For testing to be
Quality Assurance → Testing → Exploratory and Scripted Testing →
What
Here are two alternative approaches to testing a software: Scripted testing and Exploratory testing
-
Scripted testing: First write a set of test cases based on the expected behavior of the SUT, and then perform testing based on that set of test cases.
-
Exploratory testing: Devise test cases on-the-fly, creating new test cases based on the results of the past test cases.
Exploratory testing is ‘the simultaneous learning, test design, and test execution’
Here is an example thought process behind a segment of an exploratory testing session:
“Hmm... looks like feature x is broken. This usually means feature n and k could be broken too; we need to look at them soon. But before that, let us give a good test run to feature y because users can still use the product if feature y works, even if x doesn’t work. Now, if feature y doesn’t work 100%, we have a major problem and this has to be made known to the development team sooner rather than later...”
💡 Exploratory testing is also known as reactive testing, error guessing technique, attack-based testing, and bug hunting.
Exploratory Testing Explained, an online article by James Bach -- James Bach is an industry thought leader in software testing).
Scripted testing requires tests to be written in a scripting language; Manual testing is called exploratory testing.
A) False
Explanation: “Scripted” means test cases are predetermined. They need not be an executable script. However, exploratory testing is usually manual.
Which testing technique is better?
(e)
Explain the concept of exploratory testing using Minesweeper as an example.
When we test the Minesweeper by simply playing it in various ways, especially trying out those that are likely to be buggy, that would be exploratory testing.
Evidence:
Explain use case based test case design using examples from your project.
W10.6 Can use EP for test case design
W10.6a Can explain equivalence partitions
Quality Assurance → Test Case Design → Equivalence Partitions →
What
Consider the testing of the following operation.
isValidMonth(m) : returns true if m (and int) is in the range [1..12]
It is inefficient and impractical to test this method for all integer values [-MIN_INT to MAX_INT]. Fortunately, there is no need to test all possible input values. For example, if the input value 233 failed to produce the correct result, the input 234 is likely to fail too; there is no need to test both.
In general, most SUTs do not treat each input in a unique way. Instead, they process all possible inputs in a small number of distinct ways. That means a range of inputs is treated the same way inside the SUT. Equivalence partitioning (EP) is a test case design technique that uses the above observation to improve the E&E of testing.
Equivalence partition (aka equivalence class): A group of test inputs that are likely to be processed by the SUT in the same way.
By dividing possible inputs into equivalence partitions we can,
- avoid testing too many inputs from one partition. Testing too many inputs from the same partition is unlikely to find new bugs. This increases the efficiency of testing by reducing redundant test cases.
- ensure all partitions are tested. Missing partitions can result in bugs going unnoticed. This increases the effectiveness of testing by increasing the chance of finding bugs.
W10.6b Can apply EP for pure functions
Quality Assurance → Test Case Design → Equivalence Partitions →
Basic
Equivalence partitions (EPs) are usually derived from the specifications of the SUT.
These could be EPs for the
- [MIN_INT ... 0] : below the range that produces
true - [1 … 12] : the range that produces
true - [13 … MAX_INT] : above the range that produces
true
isValidMonth(m) : returns true if m (and int) is in the range [1..12]
When the SUT has multiple inputs, you should identify EPs for each input.
Consider the method duplicate(String s, int n): String which returns a String that contains s repeated n times.
Example EPs for s:
- zero-length strings
- string containing whitespaces
- ...
Example EPs for n:
0- negative values
- ...
An EP may not have adjacent values.
Consider the method isPrime(int i): boolean that returns true if i is a prime number.
EPs for i:
- prime numbers
- non-prime numbers
Some inputs have only a small number of possible values and a potentially unique behavior for each value. In those cases we have to consider each value as a partition by itself.
Consider the method showStatusMessage(GameStatus s): String that returns a unique String for each of the possible value of s (GameStatus is an enum).
In this case, each possible value for s will have to be considered as a partition.
Note that the EP technique is merely a heuristic and not an exact science, especially when applied manually (as opposed to using an automated program analysis tool to derive EPs). The partitions derived depend on how one ‘speculates’ the SUT to behave internally. Applying EP under a glass-box or gray-box approach can yield more precise partitions.
Consider the method EPs given above for the isValidMonth. A different tester might use these EPs instead:
- [1 … 12] : the range that produces
true - [all other integers] : the range that produces
false
Some more examples:
| Specification | Equivalence partitions |
|---|---|
|
|
[ |
|
|
[ |
Consider this SUT:
isValidName (String s): boolean
Description: returns true if s is not null and not longer than 50 characters.
A. Which one of these is least likely to be an equivalence partition for the parameter s of the isValidName method given below?
B. If you had to choose 3 test cases from the 4 given below, which one will you leave out based on the EP technique?
A. (d)
Explanation: The description does not mention anything about the content of the string. Therefore, the method is unlikely to behave differently for strings consisting of numbers.
B. (a) or (c)
Explanation: both belong to the same EP
W10.6c Can apply EP for OOP methods
Quality Assurance → Test Case Design → Equivalence Partitions →
Intermediate
When deciding EPs of OOP methods, we need to identify EPs of all data participants that can potentially influence the behaviour of the method, such as,
- the target object of the method call
- input parameters of the method call
- other data/objects accessed by the method such as global variables. This category may not be applicable if using the black box approach (because the test case designer using the black box approach will not know how the method is implemented)
Consider this method in the DataStack class:
push(Object o): boolean
- Adds o to the top of the stack if the stack is not full.
- returns
trueif the push operation was a success. - throws
MutabilityExceptionif the global flagFREEZE==true.InvalidValueExceptionif o is null.
EPs:
DataStackobject: [full] [not full]o: [null] [not null]FREEZE: [true][false]
Consider a simple Minesweeper app. What are the EPs for the newGame() method of the Logic component?
As newGame() does not have any parameters, the only obvious participant is the Logic object itself.
Note that if the glass-box or the grey-box approach is used, other associated objects that are involved in the method might also be included as participants. For example, Minefield object can be considered as another
participant of the newGame() method. Here, the black-box approach is assumed.
Next, let us identify equivalence partitions for each participant. Will the newGame() method behave differently for different Logic objects? If yes, how will it differ? In this case, yes, it might behave
differently based on the game state. Therefore, the equivalence partitions are:
PRE_GAME: before the game starts, minefield does not exist yetREADY: a new minefield has been created and waiting for player’s first moveIN_PLAY: the current minefield is already in useWON,LOST: let us assume thenewGamebehaves the same way for these two values
Consider the Logic component of the Minesweeper application. What are the EPs for the markCellAt(int x, int y) method?. The partitions in bold represent
valid inputs.
Logic: PRE_GAME, READY, IN_PLAY, WON, LOSTx: [MIN_INT..-1] [0..(W-1)] [W..MAX_INT] (we assume a minefield size of WxH)y: [MIN_INT..-1] [0..(H-1)] [H..MAX_INT]Cellat(x,y): HIDDEN, MARKED, CLEARED
Evidence:
Explain equivalence partitioning using examples from the project.
W10.7 Can use Boundary Value Analysis for test case design
W10.7a Can explain boundary value analysis
Quality Assurance → Test Case Design → Boundary Value Analysis →
What
Boundary Value Analysis (BVA) is test case design heuristic that is based on the observation that bugs often result from incorrect handling of boundaries of equivalence partitions. This is not surprising, as the end points of the boundary are often used in branching instructions etc. where the programmer can make mistakes.
markCellAt(int x, int y) operation could contain code such as if (x > 0 && x <= (W-1)) which involves boundaries of x’s equivalence partitions.
BVA suggests that when picking test inputs from an equivalence partition, values near boundaries (i.e. boundary values) are more likely to find bugs.
Boundary values are sometimes called corner cases.
Boundary value analysis recommends testing only values that reside on the equivalence class boundary.
False
Explanation: It does not recommend testing only those values on the boundary. It merely suggests that values on and around a boundary are more likely to cause errors.
W10.7b Can apply boundary value analysis
Quality Assurance → Test Case Design → Boundary Value Analysis →
How
Typically, we choose three values around the boundary to test: one value from the boundary, one value just below the boundary, and one value just above the boundary. The number of values to pick depends on other factors, such as the cost of each test case.
Some examples:
| Equivalence partition | Some possible boundary values |
|---|---|
|
[1-12] |
0,1,2, 11,12,13 |
|
[MIN_INT, 0] |
MIN_INT, MIN_INT+1, -1, 0 , 1 |
|
[any non-null String] |
Empty String, a String of maximum possible length |
|
[prime numbers] |
No specific boundary |
|
[non-empty Stack] |
Stack with: one element, two elements, no empty spaces, only one empty space |
🅿️ Project
W10.8 Can evolve a product incrementally
Covered by:
Tutorial 10
Show evidence of achieving mid-v1.3 team/individual milestone
- [Each member] Demo your contribution for mid-v1.3 using the jar file
Questions to discuss during tutorial
- Can you prove the code is bug free by testing?
- It is not possible to have a fully tested Windows OS. Explain why or why not?
- Explain and justify: testing should be efficient and effective
- What are the considerations for test case design?
- What is a design pattern? What are the components of a design pattern?
- When do you use Singleton pattern? Given an example other than EventCenter or Logic in AB4 that can use Singleton pattern and explain why.
- Identify the classes in AB4 that are Façades; why do you need a Façade?
- What are potential problems of using design patterns?
- Using Façade example, explain above
- Add a line that violates LoD in this code: void foo(P p) { // add code here }
- What are the differences between libraries, frameworks and platforms?
- Give examples of libraries, frameworks and platform used in AB4/your project.
- Explain the activity diagram
[source:wikipeida]
W10.1a Can explain the Law of Demeter
Supplmentary → Principles →
Law of Demeter
Law of Demeter (LoD):
- An object should have limited knowledge of another object.
- An object should only interact with objects that are closely related to it.
Also known as
- Don’t talk to strangers.
- Principle of least knowledge
More concretely, a method m of an object O should invoke only the methods of the following kinds of objects:
- The object
Oitself - Objects passed as parameters of
m - Objects created/instantiated in
m - Objects from the
direct association of O
The following code fragment violates LoD due to the reason: while b is a ‘friend’ of foo (because it receives it as a parameter), g is a ‘friend of a
friend’ (which should be considered a ‘stranger’), and g.doSomething() is analogous to ‘talking to a stranger’.
void foo(Bar b) {
Goo g = b.getGoo();
g.doSomething();
}
LoD aims to reduce coupling by limiting the interaction to a closely related group of classes.
In the example above, foo is already coupled to Bar. Upholding LoD avoids foo being coupled to Goo as well.
An analogy for LoD can be drawn from Facebook. If Facebook followed LoD, you would not be allowed to see posts of friends of friends, unless they are your friends as well. If Jake is your friend and Adam is Jake’s friend, you should not be allowed to see Adam’s posts unless Adam is a friend of yours as well.
Explain the Law of Demeter using code examples. You are to make up your own code examples. Take Minesweeper as the basis for your code examples.
Let us take the Logic class as an example. Assume that it has the following operation.
setMinefield(Minefiled mf):void
Consider the following that can happen inside this operation.
mf.init();: this does not violate LoD since LoD allows calling operations of parameters received.mf.getCell(1,3).clear();: //this violates LoD becauseLogicis handlingCellobjects deep insideMinefield. Instead, it should bemf.clearCellAt(1,3);timer.start();: //this does not violate LoD becausetimerappears to be an internal component (i.e. a variable) ofLogicitself.Cell c = new Cell();c.init();: // this does not violate LoD becausecwas created inside the operation.
This violates Law of Demeter.
void foo(Bar b) {
Goo g = new Goo();
g.doSomething();
}
False
Explanation: The line g.doSomething() does not violate LoD because it is OK to invoke methods of objects created within a method.
Pick the odd one out.
- a. Law of Demeter.
- b. Don’t add people to a late project.
- c. Don’t talk to strangers.
- d. Principle of least knowledge.
- e. Coupling.
(b)
Explanation: Law of Demeter, which aims to reduce coupling, is also known as ‘Don’t talk to strangers’ and ‘Principle of least knowledge’.
Evidence:
Identify places where LoD is followed/violated in your project.
W10.2a Can use activity diagrams
Design → Modelling → Modelling Behaviors
Activity Diagrams
Software projects often involve workflows. Workflows define the
Some examples in which a certain workflow is relevant to software project:
A software that automates the work of an insurance company needs to take into account the workflow of processing an insurance claim.
The algorithm of a price of code represents the workflow (i.e. the execution flow) of the code.
Understanding such workflows is important for the success of the software project.
Unified Modeling Language (UML) is a graphical notation to describe various aspects of a software system. UML is the brainchild of three software modeling specialists James Rumbaugh, Grady Booch and Ivar Jacobson (also known as the Three Amigos). Each of them has developed their own notation for modeling software systems before joining force to create a unified modeling language (hence, the term ‘Unified’ in UML). UML is currently the de facto modeling notation used in the software industry.
An example activity diagram [source:wikipeida]:
The most basic activity diagram is simply a linear sequence of actions.
Some workflows have alternate paths where only one of the alternate paths is taken based on some condition.
In some workflows, multiple paths happen in parallel.
Which of these sequence of actions is not allowed by the given activity diagram?
- i. start a b c d end
- ii. start a b c d e f g c d end
- iii. start a b c d e g f c d end
- iv. start a b c d g c d end
(iv)
Explanation: -e-f- and -g- are parallel paths. Both paths should complete before the execution reaches c again.
Evidence:
Use activity diagram to model workflows in the project.
W10.3c Can explain the Singleton design pattern
Design → Design Patterns → Singleton →
What
Context
A certain classes should have no more than just one instance (e.g. the main controller class of the system). These single instances are commonly known as singletons.
Problem
A normal class can be instantiated multiple times by invoking the constructor.
Solution
Make the constructor of the singleton class private, because a public constructor will allow others to instantiate the class at will. Provide a public class-level
method to access the single instance.
Example:
We use the Singleton pattern when
(c)
Evidence:
Identify where in the project Singleton pattern can be used.
W10.3d Can apply the Singleton design pattern
Design → Design Patterns → Singleton →
Implementation
Here is the typical implementation of how the Singleton pattern is applied to a class:
class Logic {
private static Logic theOne = null;
private Logic() {
...
}
public static Logic getInstance() {
if (theOne == null) {
theOne = new Logic();
}
return theOne;
}
}
Notes:
- The constructor is
private, which prevents instantiation from outside the class. - The single instance of the singleton class is maintained by a
privateclass-level variable. - Access to this object is provided by a
publicclass-level operationgetInstance()which instantiates a single copy of the singleton class when it is executed for the first time. Subsequent calls to this operation return the single instance of the class.
If Logic was not a Singleton class, an object is created like this:
Logic m = new Logic();
But now, the Logic object needs to be accessed like this:
Logic m = Logic.getInstance();
Evidence:
Identify where in the project Singleton pattern has been used. Apply singleton pattern somewhere (in a toy example or in a project)
W10.3e Can decide when to apply Singleton design
pattern
Design → Design Patterns → Singleton →
Evaluation
Pros:
- easy to apply
- effective in achieving its goal with minimal extra work
- provides an easy way to access the singleton object from anywhere in the code base
Cons:
- The singleton object acts like a global variable that increases coupling across the code base.
- In testing, it is difficult to replace Singleton objects with stubs (static methods cannot be overridden)
- In testing, singleton objects carry data from one test to another even when we want each test to be independent of the others.
Given there are some significant cons, it is recommended that you apply the Singleton pattern when, in addition to requiring only one instance of a class, there is a risk of creating multiple objects by mistake, and creating such multiple objects has real negative consequences.
Evidence:
Identify places in the project where only a single object of a class is needed but there is no need to apply the Singleton pattern.
W10.3f Can explain the Facade design pattern
Design → Design Patterns → Facade Pattern →
What
Context
Components need to access functionality deep inside other components.
The UI component of a Library system might want to access functionality of the Book class contained inside the Logic component.
Problem
Access to the component should be allowed without exposing its internal details. e.g. the UI component should access the functionality of the Logic component without knowing that it contained a Book class within it.
Solution
Include a
The following class diagram applies the Façade pattern to the Library System example. The LibraryLogic class is the Facade class.
Does the design below likely to use the Facade pattern?
True.
Facade is clearly visible (Storage is the << Facade >> class).
Evidence:
Discuss the current/potential applications of the pattern in your project.
W10.3g Can explain the Command design pattern
Design → Design Patterns → Command Pattern →
What
Context
A system is required to execute a number of commands, each doing a different task. For example, a system might have to support Sort, List, Reset commands.
Problem
It is preferable that some part of the code executes these commands without having to know each command type. e.g., there can be a CommandQueue object that is responsible for queuing commands and executing them without knowledge of what each command does.
Solution
The essential element of this pattern is to have a general << Command >> object that can be passed around, stored, executed, etc without knowing the type of command (i.e. via polymorphism).
Let us examine an example application of the pattern first:
In the example solution below, the CommandCreator creates List, Sort, and Reset Command objects and adds them to the CommandQueue object. The CommandQueue object treats them all as Command objects and performs the execute/undo operation on each of them without knowledge of the specific Command type. When executed,
each Command object will access the DataStore object to carry out its task. The Command class can also be an abstract class or an interface.
The general form of the solution is as follows.
The << Client >> creates a << ConcreteCommand >> object, and passes it to the << Invoker >>. The << Invoker >> object treats all
commands as a general << Command >> type. << Invoker >> issues a request by calling execute() on the command. If a command is undoable, << ConcreteCommand >> will store the state for undoing the command prior to invoking execute(). In addition, the << ConcreteCommand >> object may have to be linked to any << Receiver >> of the command (
<< Invoker >>. Note that an application of the command pattern does not have to follow the structure given above.
Evidence:
Discuss the current/potential applications of the pattern in your project.
W10.4b Can explain the costs and benefits of reuse
Implementation → Reuse → Introduction →
When
While you may be tempted to use many libraries/frameworks/platform that seem to crop up on a regular basis and promise to bring great benefits, note that there are costs associated with reuse. Here are some:
- The reused code may be an overkill (think using a sledgehammer to crack a nut) increasing the size of, or/and degrading the performance of, your software.
- The reused software may not be mature/stable enough to be used in an important product. That means the software can change drastically and rapidly, possibly in ways that break your software.
- Non-mature software has the risk of dying off as fast as they emerged, leaving you with a dependency that is no longer maintained.
- The license of the reused software (or its dependencies) restrict how you can use/develop your software.
- The reused software might have bugs, missing features, or security vulnerabilities that are important to your product but not so important to the maintainers of that software, which means those flaws will not get fixed as fast as you need them to.
- Malicious code can sneak into your product via compromised dependencies.
One of your teammates is proposing to use a recently-released “cool” UI framework for your class project. List the pros and cons of this idea.
Pros
- The potential to create a much better product by reusing the framework.
- Learning a new framework is good for the future job prospects.
Cons
- Learning curve may be steep.
- May not be stable (it was recently released).
- May not allow us to do exactly what we want. While frameworks allow customization, such customization can be limited.
- Performance penalties.
- Might interfere with learning objectives of the module.
Note that having more cons does not mean we should not use this framework. Further investigation is required before we can make a final decision.
Evidence:
Have reused software. Can explain general costs and benefits of the code you have reused.
W10.4c Can explain libraries
Implementation → Reuse → Libraries →
What
A library is a collection of modular code that is general and can be used by other programs.
Java classes you get with the JDK (such as String, ArrayList, HashMap, etc.) are library classes that are provided in the default Java distribution.
Natty is a Java library that can be used for parsing strings that represent dates e.g. The 31st of April in the year 2008
built-in modules you get with Python (such as csv, random, sys, etc.) are libraries that are provided in the default Python distribution. Classes such
as list, str, dict are built-in library classes that you get with Python.
Colorama is a Python library that can be used for colorizing text in a CLI.
Evidence:
Identify libraries used (or potentially usable) in your project.
W10.4d Can make use of a library
Implementation → Reuse → Libraries →
How
These are the typical steps required to use a library.
- Read the documentation to confirm that its functionality fits your needs
- Check the license to confirm that it allows reuse in the way you plan to reuse it. For example, some libraries might allow non-commercial use only.
- Download the library and make it accessible to your project. Alternatively, you can configure your
dependency management tool to do it for you. - Call the library API from your code where you need to use the library functionality.
Evidence:
Have used libraries (or reused code from elsewhere) in your project.
W10.4e Can explain frameworks
Implementation → Reuse → Frameworks →
What
The overall structure and execution flow of a specific category of software systems can be very similar. The similarity is an opportunity to reuse at a high scale.
Running example:
IDEs for different programming languages are similar in how they support editing code, organizing project files, debugging, etc.
A software framework is a reusable implementation of a software (or part thereof) providing generic functionality that can be selectively customized to produce a specific application.
Running example:
Eclipse is an IDE framework that can be used to create IDEs for different programming languages.
Some frameworks provide a complete implementation of a default behavior which makes them immediately usable.
Running example:
Eclipse is a fully functional Java IDE out-of-the-box.
A framework facilitates the adaptation and customization of some desired functionality.
Running example:
Eclipse plugin system can be used to create an IDE for different programming languages while reusing most of the existing IDE features of Eclipse. E.g. https://marketplace.eclipse.org/content/pydev-python-ide-eclipse
Some frameworks cover only a specific components or an aspect.
JavaFx a framework for creating Java GUIs. TkInter is a GUI framework for Python.
More examples of frameworks
- Frameworks for Web-based applications: Drupal(PHP), Django(Python), Ruby on Rails (Ruby), Spring (Java)
- Frameworks for testing: JUnit (Java), unittest (Python), Jest (Java Script)
Evidence:
Identify frameworks used (or potentially usable) in your project.
W10.4f Can differentiate between frameworks and
libraries
Implementation → Reuse → Frameworks →
Frameworks vs Libraries
Although both frameworks and libraries are reuse mechanisms, there are notable differences:
-
Libraries are meant to be used ‘as is’ while frameworks are meant to be customized/extended. e.g., writing plugins for Eclipse so that it can be used as an IDE for different languages (C++, PHP, etc.), adding modules and themes to Drupal, and adding test cases to JUnit.
-
Your code calls the library code while the framework code calls your code. Frameworks use a technique called inversion of control, aka the “Hollywood principle” (i.e. don’t call us, we’ll call you!). That is, you write code that will be called by the framework, e.g. writing test methods that will be called by the JUnit framework. In the case of libraries, your code calls libraries.
Choose correct statements about software frameworks.
- a. They follow the hollywood principle, otherwise known as ‘inversion of control’
- b. They come with full or partial implementation.
- c. They are more concrete than patterns or principles.
- d. They are often configurable.
- e. They are reuse mechanisms.
- f. They are similar to reusable libraries but bigger.
(a)(b)(c)(d)(e)(f)
Explanation: While both libraries and frameworks are reuse mechanisms, and both more concrete than principles and patterns, libraries differ from frameworks in some key ways. One of them is the ‘inversion of control’ used by frameworks but not libraries. Furthermore, frameworks do not have to be bigger than libraries all the time.
Which one of these are frameworks ?
(a)(b)(c)(d)
Explanation: These are frameworks.
Evidence:
Explain the difference between libraries and frameworks using frameworks and libraries in your project as examples.
W10.4g Can explain platforms
Implementation → Reuse → Platforms →
What
A platform provides a runtime environment for applications. A platform is often bundled with various libraries, tools, frameworks, and technologies in addition to a runtime environment but the defining characteristic of a software platform is the presence of a runtime environment.
Technically, an operating system can be called a platform. For example, Windows PC is a platform for desktop applications while iOS is a platform for mobile apps.
Two well-known examples of platforms are JavaEE and .NET, both of which sit above Operating systems layer, and are used to develop
- JavaEE (Java Enterprise Edition) is both a framework and a platform for writing enterprise applications. The runtime used by the JavaEE applications is the JVM (Java Virtual Machine) that can run on different Operating Systems.
- .NET is a similar platform and a framework. Its runtime is called CLR (Common Language Runtime) and usually used on Windows machines.
Enterprise Application: ‘enterprise applications’ means software applications used at organizations level and therefore has to meet much higher demands (such as in scalability, security, performance, and robustness) than software meant for individual use.
Evidence:
Identify platforms used (or potentially usable) in your project.
W10.5a Can explain the need for deliberate test
case design
Quality Assurance → Test Case Design → Introduction →
What
Except for trivial
Consider the test cases for adding a string object to a
- Add an item to an empty collection.
- Add an item when there is one item in the collection.
- Add an item when there are 2, 3, .... n items in the collection.
- Add an item that has an English, a French, a Spanish, ... word.
- Add an item that is the same as an existing item.
- Add an item immediately after adding another item.
- Add an item immediately after system startup.
- ...
Exhaustive testing of this operation can take many more test cases.
Program testing can be used to show the presence of bugs, but never to show their absence!
--Edsger Dijkstra
Every test case adds to the cost of testing. In some systems, a single test case can cost thousands of dollars e.g. on-field testing of flight-control software. Therefore, test cases need to be designed to make the best use of testing resources. In particular:
-
Testing should be effective i.e., it finds a high percentage of existing bugs e.g., a set of test cases that finds 60 defects is more effective than a set that finds only 30 defects in the same system.
-
Testing should be efficient i.e., it has a high rate of success (bugs found/test cases) a set of 20 test cases that finds 8 defects is more efficient than another set of 40 test cases that finds the same 8 defects.
For testing to be
Given below is the sample output from a text-based program TriangleDetector ithat determines whether the three input numbers make up the three sides of a valid triangle. List test cases you would use to test
this software. Two sample test cases are given below.
C:\> java TriangleDetector
Enter side 1: 34
Enter side 2: 34
Enter side 3: 32
Can this be a triangle?: Yes
Enter side 1:
Sample test cases,
34,34,34: Yes
0, any valid, any valid: No
In addition to obvious test cases such as
- sum of two sides == third,
- sum of two sides < third ...
We may also devise some interesting test cases such as the ones depicted below.
Note that their applicability depends on the context in which the software is operating.
- Non-integer number, negative numbers,
0, numbers formatted differently (e.g.13F), very large numbers (e.g.MAX_INT), numbers with many decimal places, empty string, ... - Check many triangles one after the other (will the system run out of memory?)
- Backspace, tab, CTRL+C , …
- Introduce a long delay between entering data (will the program be affected by, say the screensaver?), minimize and restore window during the operation, hibernate the system in the middle of a calculation, start with invalid inputs (the system may perform error handling differently for the very first test case), …
- Test on different locale.
The main point to note is how difficult it is to test exhaustively, even on a trivial system.
Explain the why exhaustive testing is not practical using the example of testing newGame() operation in the Logic class of a Minesweeper game.
Consider this sequence of test cases:
- Test case 1. Start Minesweeper. Activate
newGame()and see if it works. - Test case 2. Start Minesweeper. Activate
newGame(). ActivatenewGame()again and see if it works. - Test case 3. Start Minesweeper. Activate
newGame()three times consecutively and see if it works. - …
- Test case 267. Start Minesweeper. Activate
newGame()267 times consecutively and see if it works.
Well, you get the idea. Exhaustive testing of newGame() is not practical.
Improving efficiency and effectiveness of test case design can,
- a. improve the quality of the SUT.
- b. save money.
- c. save time spent on test execution.
- d. save effort on writing and maintaining tests.
- e. minimize redundant test cases.
- f. forces us to understand the SUT better.
(a)(b)(c)(d)(e)(f)
Evidence:
Explain why testing needs to be E&E, using examples from your project.
W10.5b Can explain exploratory testing and scripted
testing
Quality Assurance → Testing → Exploratory and Scripted Testing →
What
Here are two alternative approaches to testing a software: Scripted testing and Exploratory testing
-
Scripted testing: First write a set of test cases based on the expected behavior of the SUT, and then perform testing based on that set of test cases.
-
Exploratory testing: Devise test cases on-the-fly, creating new test cases based on the results of the past test cases.
Exploratory testing is ‘the simultaneous learning, test design, and test execution’
Here is an example thought process behind a segment of an exploratory testing session:
“Hmm... looks like feature x is broken. This usually means feature n and k could be broken too; we need to look at them soon. But before that, let us give a good test run to feature y because users can still use the product if feature y works, even if x doesn’t work. Now, if feature y doesn’t work 100%, we have a major problem and this has to be made known to the development team sooner rather than later...”
💡 Exploratory testing is also known as reactive testing, error guessing technique, attack-based testing, and bug hunting.
Exploratory Testing Explained, an online article by James Bach -- James Bach is an industry thought leader in software testing).
Scripted testing requires tests to be written in a scripting language; Manual testing is called exploratory testing.
A) False
Explanation: “Scripted” means test cases are predetermined. They need not be an executable script. However, exploratory testing is usually manual.
Which testing technique is better?
(e)
Explain the concept of exploratory testing using Minesweeper as an example.
When we test the Minesweeper by simply playing it in various ways, especially trying out those that are likely to be buggy, that would be exploratory testing.
Evidence:
Explain exploratory and scripted testing in the context of your project.
W10.5d Can explain positive and negative test
cases
Quality Assurance → Test Case Design → Introduction →
Positive vs Negative Test Cases
A positive test case is when the test is designed to produce an expected/valid behavior. A negative test case is designed to produce a behavior that indicates an invalid/unexpected situation, such as an error message.
Consider testing of the method print(Integer i) which prints the value of i.
- A positive test case:
i == new Integer(50) - A negative test case:
i == null;
Evidence:
Give examples of positive and negative test cases from your project.
W10.5e Can explain black box and glass box test
case design
Quality Assurance → Test Case Design → Introduction →
Black Box vs Glass Box
Test case design can be of three types, based on how much of SUT internal details are considered when designing test cases:
-
Black-box (aka specification-based or responsibility-based) approach: test cases are designed exclusively based on the SUT’s specified external behavior.
-
White-box (aka glass-box or structured or implementation-based) approach: test cases are designed based on what is known about the SUT’s implementation, i.e. the code.
-
Gray-box approach: test case design uses some important information about the implementation. For example, if the implementation of a sort operation uses different algorithms to sort lists shorter than 1000 items and lists longer than 1000 items, more meaningful test cases can then be added to verify the correctness of both algorithms.
Note: these videos are from the Udacity course Software Development Process by Georgia Tech
Evidence:
Explain black/white/grey box testing using examples from your project.
W10.5f Can explain test case design for use case
based testing
Quality Assurance → Test Case Design →
Testing Based on Use Cases
Use cases can be used for system testing and acceptance testing. For example, the main success scenario can be one test case while each variation (due to extensions) can form another test case. However, note that
use cases do not specify the exact data entered into the system. Instead, it might say something like user enters his personal data into the system. Therefore, the tester has to choose data by considering equivalence
partitions and boundary values. The combinations of these could result in one use case producing many test cases.
To increase
Every test case adds to the cost of testing. In some systems, a single test case can cost thousands of dollars e.g. on-field testing of flight-control software. Therefore, test cases need to be designed to make the best use of testing resources. In particular:
-
Testing should be effective i.e., it finds a high percentage of existing bugs e.g., a set of test cases that finds 60 defects is more effective than a set that finds only 30 defects in the same system.
-
Testing should be efficient i.e., it has a high rate of success (bugs found/test cases) a set of 20 test cases that finds 8 defects is more efficient than another set of 40 test cases that finds the same 8 defects.
For testing to be
Quality Assurance → Testing → Exploratory and Scripted Testing →
What
Here are two alternative approaches to testing a software: Scripted testing and Exploratory testing
-
Scripted testing: First write a set of test cases based on the expected behavior of the SUT, and then perform testing based on that set of test cases.
-
Exploratory testing: Devise test cases on-the-fly, creating new test cases based on the results of the past test cases.
Exploratory testing is ‘the simultaneous learning, test design, and test execution’
Here is an example thought process behind a segment of an exploratory testing session:
“Hmm... looks like feature x is broken. This usually means feature n and k could be broken too; we need to look at them soon. But before that, let us give a good test run to feature y because users can still use the product if feature y works, even if x doesn’t work. Now, if feature y doesn’t work 100%, we have a major problem and this has to be made known to the development team sooner rather than later...”
💡 Exploratory testing is also known as reactive testing, error guessing technique, attack-based testing, and bug hunting.
Exploratory Testing Explained, an online article by James Bach -- James Bach is an industry thought leader in software testing).
Scripted testing requires tests to be written in a scripting language; Manual testing is called exploratory testing.
A) False
Explanation: “Scripted” means test cases are predetermined. They need not be an executable script. However, exploratory testing is usually manual.
Which testing technique is better?
(e)
Explain the concept of exploratory testing using Minesweeper as an example.
When we test the Minesweeper by simply playing it in various ways, especially trying out those that are likely to be buggy, that would be exploratory testing.
Evidence:
Explain use case based test case design using examples from your project.
W10.6c Can apply EP for OOP methods
Quality Assurance → Test Case Design → Equivalence Partitions →
Intermediate
When deciding EPs of OOP methods, we need to identify EPs of all data participants that can potentially influence the behaviour of the method, such as,
- the target object of the method call
- input parameters of the method call
- other data/objects accessed by the method such as global variables. This category may not be applicable if using the black box approach (because the test case designer using the black box approach will not know how the method is implemented)
Consider this method in the DataStack class:
push(Object o): boolean
- Adds o to the top of the stack if the stack is not full.
- returns
trueif the push operation was a success. - throws
MutabilityExceptionif the global flagFREEZE==true.InvalidValueExceptionif o is null.
EPs:
DataStackobject: [full] [not full]o: [null] [not null]FREEZE: [true][false]
Consider a simple Minesweeper app. What are the EPs for the newGame() method of the Logic component?
As newGame() does not have any parameters, the only obvious participant is the Logic object itself.
Note that if the glass-box or the grey-box approach is used, other associated objects that are involved in the method might also be included as participants. For example, Minefield object can be considered as another
participant of the newGame() method. Here, the black-box approach is assumed.
Next, let us identify equivalence partitions for each participant. Will the newGame() method behave differently for different Logic objects? If yes, how will it differ? In this case, yes, it might
behave differently based on the game state. Therefore, the equivalence partitions are:
PRE_GAME: before the game starts, minefield does not exist yetREADY: a new minefield has been created and waiting for player’s first moveIN_PLAY: the current minefield is already in useWON,LOST: let us assume thenewGamebehaves the same way for these two values
Consider the Logic component of the Minesweeper application. What are the EPs for the markCellAt(int x, int y) method?. The partitions in bold represent
valid inputs.
Logic: PRE_GAME, READY, IN_PLAY, WON, LOSTx: [MIN_INT..-1] [0..(W-1)] [W..MAX_INT] (we assume a minefield size of WxH)y: [MIN_INT..-1] [0..(H-1)] [H..MAX_INT]Cellat(x,y): HIDDEN, MARKED, CLEARED
Evidence:
Explain equivalence partitioning using examples from the project.
W10.8 Can evolve a product incrementally
Covered by:
Lecture 10
Slides: Uploaded on IVLE.