Full Schedule of Module Activities
Admin info to read:
Overview: Tweak as per peer-testing results, draft Project Portfolio Page, practice product demo.
Project Management:
- Freeze features around this time. Ensure the current product have all the features you intend to release at v1.4. Adding major changes after this point is risky. The remaining time is better spent fixing problems discovered late or on fine-tuning the product.
- Ensure the code attributed to you by RepoSense is correct, as reported in the Code Dashboard
Relevant: [
In previous semesters we asked students to annotate all their code using special @@author tags so that we can extract each student's code for grading. This semester, we are trying out a new tool called RepoSense
that is expected to reduce the need for such tagging, and also make it easier for you to see (and learn from) code written by others.
1. View the current status of code authorship data:
- The report generated by the tool is available at Code Dashboard (BETA). The feature that is most relevant to you is the Code Panel (shown on the right side of the screenshot above). It shows the code attributed to a given author. You are welcome to play around with the other features (they are still under development and will not be used for grading this semester).
- Click on your name to load the code attributed to you (based on Git blame/log data) onto the code panel on the right.
- If the code shown roughly matches the code you wrote, all is fine and there is nothing for you to do.
2. If the code does not match:
-
Here are the possible reasons for the code shown not to match the code you wrote:
- the git username in some of your commits does not match your GitHub username (perhaps you missed our instructions to set your Git username to match GitHub username earlier in the project, or GitHub did not honor your Git username for some reason)
- the actual authorship does not match the authorship determined by git blame/log e.g., another student touched your code after you wrote it, and Git log attributed the code to that student instead
-
In those cases,
- Install RepoSense (see the Getting Started section of the RepoSense User Guide)
- Use the two methods described in the RepoSense User Guide section Configuring a Repo to Provide Additional Data to RepoSense to provide additional data to the authorship analysis to make it more accurate.
- If you add a
config.jsonfile to your repo (as specified by one of the two methods),- Please use the template json file given in the module website so that your display name matches the name we expect it to be.
- If your commits have multiple author names, specify all of them e.g.,
"authorNames": ["theMyth", "theLegend", "theGary"] - Update the line
config.jsonin the.gitignorefile of your repo as/config.jsonso that it ignores theconfig.jsonproduced by the app but not the_reposense/config.json.
- If you add
@@authorannotations, please follow the guidelines below:
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
- After you are satisfied with the new results (i.e., results produced by running RepoSense locally), push the
config.jsonfile you added and/or the annotated code to your repo. We'll use that information the next time we run RepoSense (we run it at least once a week). - If you choose to annotate code, please annotate code chunks not smaller than a method. We do not grade code snippets smaller than a method.
- If you encounter any problem when doing the above or if you have questions, please post in the forum.
We recommend you ensure your code is RepoSense-compatible by v1.3
Product:
- Consider increasing code coverage by adding more tests if it is lower than the level you would like it to be. Take note of
our expectation on test code . - After you have sufficient code coverage, fix remaining code quality problems and bring up the quality to your target level.
- There is no requirement for a minimum coverage level. Note that in a production environment you are often required to have at least 90% of the code covered by tests. In this project, it can be less. The less coverage you have, the higher the risk of regression bugs, which will cost marks if not fixed before the final submission.
- You must write some tests so that we can evaluate your ability to write tests.
- How much of each type of testing should you do? We expect you to decide. You learned different types of testing and what they try to achieve. Based on that, you should decide how much of each type is required. Similarly, you can decide to what extent you want to automate tests, depending on the benefits and the effort required.
- Applying TDD is optional. If you plan to test something, it is better to apply TDD because TDD ensures that you write functional code in a testable way. If you do it the normal way, you often find that it is hard to test the functional code because the code has low testability.
Relevant: [
-
Ensure your code has at least some evidence of these (see here for more info)
- logging
- exceptions
- assertions
- defensive coding
-
Ensure there are no coding standard violations e.g. all boolean variables/methods sounds like booleans. Checkstyle can prevent only some coding standard violations; others need to be checked manually.
-
Ensure SLAP is applied at a reasonable level. Long methods or deeply-nested code are symptoms of low-SLAP may be counted against your code quality.
-
Reduce code duplications i.e. if there multiple blocks of code that vary only in minor ways, try to extract out similarities into one place, especially in test code.
-
In addition, try to apply as many of the
code quality guidelines covered in the module as much as you can.
Code Quality
Introduction
Basic
Can explain the importance of code quality
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Guideline: Maximise Readability
Introduction
Can explain the importance of readability
Programs should be written and polished until they acquire publication quality. --Niklaus Wirth
Among various dimensions of code quality, such as run-time efficiency, security, and robustness, one of the most important is understandability. This is because in any non-trivial software project, code needs to be read, understood, and modified by other developers later on. Even if we do not intend to pass the code to someone else, code quality is still important because we all become 'strangers' to our own code someday.
The two code samples given below achieve the same functionality, but one is easier to read.
|
Bad |
|
Good |
|
Bad |
|
Good |
Basic
Avoid Long Methods
Can improve code quality using technique: avoid long methods
Be wary when a method is longer than the computer screen, and take corrective action when it goes beyond 30 LOC (lines of code). The bigger the haystack, the harder it is to find a needle.
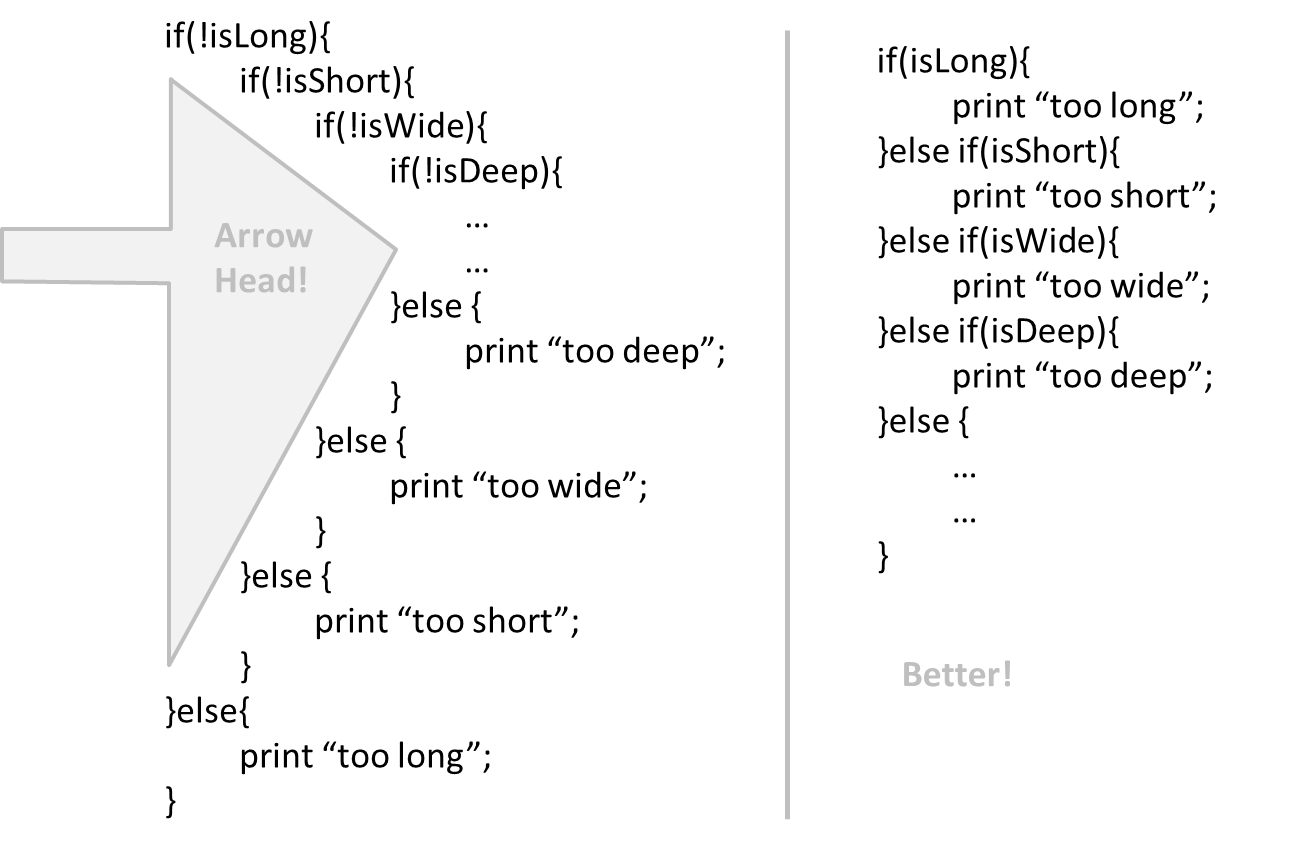
Avoid Deep Nesting
Can improve code quality using technique: avoid deep nesting
If you need more than 3 levels of indentation, you're screwed anyway, and should fix your program. --Linux 1.3.53 CodingStyle
In particular, avoid arrowhead style code.
Example:
Avoid Complicated Expressions
Can improve code quality using technique: avoid complicated expressions
Avoid complicated expressions, especially those having many negations and nested parentheses. If you must evaluate complicated expressions, have it done in steps (i.e. calculate some intermediate values first and use them to calculate the final value).
Example:
Bad
return ((length < MAX_LENGTH) || (previousSize != length)) && (typeCode == URGENT);
Good
boolean isWithinSizeLimit = length < MAX_LENGTH;
boolean isSameSize = previousSize != length;
boolean isValidCode = isWithinSizeLimit || isSameSize;
boolean isUrgent = typeCode == URGENT;
return isValidCode && isUrgent;
Example:
Bad
return ((length < MAX_LENGTH) or (previous_size != length)) and (type_code == URGENT)
Good
is_within_size_limit = length < MAX_LENGTH
is_same_size = previous_size != length
is_valid_code = is_within_size_limit or is_same_size
is_urgent = type_code == URGENT
return is_valid_code and is_urgent
The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague. -- Edsger Dijkstra
Avoid Magic Numbers
Can improve code quality using technique: avoid magic numbers
When the code has a number that does not explain the meaning of the number, we call that a magic number (as in “the number appears as if by magic”). Using a
Example:
|
Bad |
|
Good |
Note: Python does not have a way to make a variable a constant. However, you can use a normal variable with an ALL_CAPS name to simulate a constant.
|
Bad |
|
Good |
Similarly, we can have ‘magic’ values of other data types.
Bad
"Error 1432" // A magic string!
Make the Code Obvious
Can improve code quality using technique: make the code obvious
Make the code as explicit as possible, even if the language syntax allows them to be implicit. Here are some examples:
- [
Java] Use explicit type conversion instead of implicit type conversion. - [
Java,Python] Use parentheses/braces to show grouping even when they can be skipped. - [
Java,Python] Useenumerations when a certain variable can take only a small number of finite values. For example, instead of declaring the variable 'state' as an integer and using values 0,1,2 to denote the states 'starting', 'enabled', and 'disabled' respectively, declare 'state' as typeSystemStateand define an enumerationSystemStatethat has values'STARTING','ENABLED', and'DISABLED'.
Intermediate
Structure Code Logically
Can improve code quality using technique: structure code logically
Lay out the code so that it adheres to the logical structure. The code should read like a story. Just like we use section breaks, chapters and paragraphs to organize a story, use classes, methods, indentation and line spacing in your code to group related segments of the code. For example, you can use blank lines to group related statements together. Sometimes, the correctness of your code does not depend on the order in which you perform certain intermediary steps. Nevertheless, this order may affect the clarity of the story you are trying to tell. Choose the order that makes the story most readable.
Do Not 'Trip Up' Reader
Can improve code quality using technique: do not 'trip up' reader
Avoid things that would make the reader go ‘huh?’, such as,
- unused parameters in the method signature
- similar things look different
- different things that look similar
- multiple statements in the same line
- data flow anomalies such as, pre-assigning values to variables and modifying it without any use of the pre-assigned value
Practice KISSing
Can improve code quality using technique: practice kissing
As the old adage goes, "keep it simple, stupid” (KISS). Do not try to write ‘clever’ code. For example, do not dismiss the brute-force yet simple solution in favor of a complicated one because of some ‘supposed benefits’ such as 'better reusability' unless you have a strong justification.
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. --Brian W. Kernighan
Programs must be written for people to read, and only incidentally for machines to execute. --Abelson and Sussman
Avoid Premature Optimizations
Can improve code quality using technique: avoid premature optimizations
Optimizing code prematurely has several drawbacks:
- We may not know which parts are the real performance bottlenecks. This is especially the case when the code undergoes transformations (e.g. compiling, minifying, transpiling, etc.) before it becomes an executable. Ideally, you should use a profiler tool to identify the actual bottlenecks of the code first, and optimize only those parts.
- Optimizing can complicate the code, affecting correctness and understandability
- Hand-optimized code can be harder for the compiler to optimize (the simpler the code, the easier for the compiler to optimize it). In many cases a compiler can do a better job of optimizing the runtime code if you don't get in the way by trying to hand-optimize the source code.
A popular saying in the industry is make it work, make it right, make it fast which means in most cases getting the code to perform correctly should take priority over optimizing it. If the code doesn't work correctly, it has no value on matter how fast/efficient it it.
Premature optimization is the root of all evil in programming. --Donald Knuth
Note that there are cases where optimizing takes priority over other things e.g. when writing code for resource-constrained environments. This guideline simply a caution that you should optimize only when it is really needed.
SLAP Hard
Can improve code quality using technique: SLAP hard
Avoid varying the level of
Example:
Bad
readData();
salary = basic*rise+1000;
tax = (taxable?salary*0.07:0);
displayResult();
Good
readData();
processData();
displayResult();
Design → Design Fundamentals → Abstraction →
What
Abstraction is a technique for dealing with complexity. It works by establishing a level of complexity (or an aspect) we are interested in, and suppressing the more complex details below that level (or irrelevant to that aspect).
Most programs are written to solve complex problems involving large amounts of intricate details. It is impossible to deal with all these details at the same time. The guiding principle of abstraction stipulates that we capture only details that are relevant to the current perspective or the task at hand.
Ignoring lower level data items and thinking in terms of bigger entities is called data abstraction.
Within a certain software component, we might deal with a user data type, while ignoring the details contained in the user data item such as name, and date of birth. These details have been ‘abstracted away’ as they do not affect the task of that software component.
Control abstraction abstracts away details of the actual control flow to focus on tasks at a simplified level.
print(“Hello”) is an abstraction of the actual output mechanism within the computer.
Abstraction can be applied repeatedly to obtain progressively higher levels of abstractions.
An example of different levels of data abstraction: a File is a data item that is at a higher level than an array and an array is at a higher
level than a bit.
An example of different levels of control abstraction: execute(Game) is at a higher level than print(Char) which is at a higher
than an Assembly language instruction MOV.
Advanced
Make the Happy Path Prominent
Can improve code quality using technique: make the happy path prominent
The happy path (i.e. the execution path taken when everything goes well) should be clear and prominent in your code. Restructure the code to make the happy path unindented as much as possible. It is the ‘unusual’ cases that should be indented. Someone reading the code should not get distracted by alternative paths taken when error conditions happen. One technique that could help in this regard is the use of guard clauses.
Example:
Bad
if (!isUnusualCase) { //detecting an unusual condition
if (!isErrorCase) {
start(); //main path
process();
cleanup();
exit();
} else {
handleError();
}
} else {
handleUnusualCase(); //handling that unusual condition
}
In the code above,
- Unusual condition detection is separated from their handling.
- Main path is nested deeply.
Good
if (isUnusualCase) { //Guard Clause
handleUnusualCase();
return;
}
if (isErrorCase) { //Guard Clause
handleError();
return;
}
start();
process();
cleanup();
exit();
In contrast, the above code
- deals with unusual conditions as soon as they are detected so that the reader doesn't have to remember them for long.
- keeps the main path un-indented.
Guideline: Follow a Standard
Introduction
Can explain the need for following a standard
One essential way to improve code quality is to follow a consistent style. That is why software engineers follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire code base look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the location of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company use the same coding standard and that standard is not generally inconsistent with typical industry practices. If a company's coding standards is very different from what is used typically in the industry, new recruits will take longer to get used to the company's coding style.
💡 IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
What is the recommended approach regarding coding standards?
c
What is the aim of using a coding standard? How does it help?
Basic
Can follow simple mechanical style rules
Learn basic guidelines of the Java coding standard (by OSS-Generic)
Sample coding standard: PEP 8 Python Style Guide -- by Python.org
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Intermediate
Can follow intermediate style rules
Go through the provided Java coding standard and learn the intermediate style rules.
According to the given Java coding standard, which one of these is not a good name?
b
Explanation: checkWeight is an action. Naming variables as actions makes the code harder to follow. isWeightValid may be a better name.
Repeat the exercise in the panel below but also find violations of intermediate level guidelines.
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Here's one you are more likely to miss:
* Print the description as a string.→* Prints the description as a string.
There are more.
Guideline: Name Well
Introduction
Can explain the need for good names in code
Proper naming improves the readability. It also reduces bugs caused by ambiguities regarding the intent of a variable or a method.
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
Basic
Use Nouns for Things and Verbs for Actions
Can improve code quality using technique: use nouns for things and verbs for actions
Use nouns for classes/variables and verbs for methods/functions.
Examples:
| Name for a | Bad | Good |
|---|---|---|
| Class | CheckLimit |
LimitChecker |
| method | result() |
calculate() |
Distinguish clearly between single-valued and multivalued variables.
Examples:
Good
Person student;
ArrayList<Person> students;
Good
student = Person('Jim')
students = [Person('Jim'), Person('Alice')]
Use Standard Words
Can improve code quality using technique: use standard words
Use correct spelling in names. Avoid 'texting-style' spelling. Avoid foreign language words, slang, and names that are only meaningful within specific contexts/times e.g. terms from private jokes, a TV show currently popular in your country
Intermediate
Use Name to Explain
Can improve code quality using technique: use name to explain
A name is not just for differentiation; it should explain the named entity to the reader accurately and at a sufficient level of detail.
Examples:
| Bad | Good |
|---|---|
processInput() (what 'process'?) |
removeWhiteSpaceFromInput() |
flag |
isValidInput |
temp |
If the name has multiple words, they should be in a sensible order.
Examples:
| Bad | Good |
|---|---|
bySizeOrder() |
orderBySize() |
Imagine going to the doctor's and saying "My eye1 is swollen"! Don’t use numbers or case to distinguish names.
Examples:
| Bad | Bad | Good |
|---|---|---|
value1, value2 |
value, Value |
originalValue, finalValue |
Not Too Long, Not Too Short
Can improve code quality using technique: not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
Avoid Misleading Names
Can improve code quality using technique: avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color blackcolorWhite: hex value for color whitecolorBlue: number of times blue is usedhexForRed: : hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently
but has very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRedblueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Examples:
| Bad | Good | Reason |
|---|---|---|
phase0 |
phaseZero |
Is that zero or letter O? |
rwrLgtDirn |
rowerLegitDirection |
Hard to pronounce |
right left wrong |
rightDirection leftDirection wrongResponse |
right is for 'correct' or 'opposite of 'left'? |
redBooks readBooks |
redColorBooks booksRead |
red and read (past tense) sounds the same |
FiletMignon |
egg |
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon |
Guideline: Avoid Unsafe Shortcuts
Introduction
Can explain the need for avoiding error-prone shortcuts
It is safer to use language constructs in the way they are meant to be used, even if the language allows shortcuts. Some such coding practices are common sources of bugs. Know them and avoid them.
Basic
Use the Default Branch
Can improve code quality using technique: use the default branch
Always include a default branch in case statements.
Furthermore, use it for the intended default action and not just to execute the last option. If there is no default action, you can use the 'default' branch to detect errors (i.e. if execution reached
the default branch, throw an exception). This also applies to the final else of an if-else construct. That is, the final else should mean 'everything
else', and not the final option. Do not use else when an if condition can be explicitly specified, unless there is absolutely no other possibility.
Bad
if (red) print "red";
else print "blue";
Good
if (red) print "red";
else if (blue) print "blue";
else error("incorrect input");
Don't Recycle Variables or Parameters
Can improve code quality using technique: don't recycle variables or parameters
- Use one variable for one purpose. Do not reuse a variable for a different purpose other than its intended one, just because the data type is the same.
- Do not reuse formal parameters as local variables inside the method.
Bad
double computeRectangleArea(double length, double width) {
length = length * width;
return length;
}
Good
double computeRectangleArea(double length, double width) {
double area;
area = length * width;
return area;
}
Avoid Empty Catch Blocks
Can improve code quality using technique: avoid empty catch blocks
Never write an empty catch statement. At least give a comment to explain why the catch block is left empty.
Delete Dead Code
Can improve code quality using technique: delete dead code
We all feel reluctant to delete code we have painstakingly written, even if we have no use for that code any more ("I spent a lot of time writing that code; what if we need it again?"). Consider all code as baggage you have to carry; get rid of unused code the moment it becomes redundant. If you need that code again, simply recover it from the revision control tool you are using. Deleting code you wrote previously is a sign that you are improving.
Intermediate
Minimise Scope of Variables
Can improve code quality using technique: minimise scope of variables
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside
that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used. -- Effective Java, by Joshua Bloch
Resources:
Minimise Code Duplication
Can improve code quality using technique: minimise code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the
Supplmentary → Principles →
DRY Principle
DRY (Don't Repeat Yourself) Principle: Every piece of knowledge must have a single, unambiguous, authoritative representation within a system The Pragmatic Programmer, by Andy Hunt and Dave Thomas
This principle guards against duplication of information.
The functionality implemented twice is a violation of the DRY principle even if the two implementations are different.
The value a system-wide timeout being defined in multiple places is a violation of DRY.
Guideline: Comment Minimally, but Sufficiently
Introduction
Can explain the need for commenting minimally but sufficiently
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer. --Steve McConnell, Author of Clean Code
Some think commenting heavily increases the 'code quality'. This is not so. Avoid writing comments to explain bad code. Improve the code to make it self-explanatory.
Basic
Do Not Repeat the Obvious
Can improve code quality using technique: do not repeat the obvious
If the code is self-explanatory, refrain from repeating the description in a comment just for the sake of 'good documentation'.
Bad
// increment x
x++;
//trim the input
trimInput();
Write to the Reader
Can improve code quality using technique: write to the reader
Do not write comments as if they are private notes to self. Instead, write them well enough to be understood by another programmer. One type of comments that is almost always useful is the header comment that you write for a class or an operation to explain its purpose.
Examples:
Bad Reason: this comment will only make sense to the person who wrote it
// a quick trim function used to fix bug I detected overnight
void trimInput(){
....
}
Good
/** Trims the input of leading and trailing spaces */
void trimInput(){
....
}
Bad Reason: this comment will only make sense to the person who wrote it
# a quick trim function used to fix bug I detected overnight
def trim_input():
...
Good
def trim_input():
"""Trim the input of leading and trailing spaces"""
...
Intermediate
Explain WHAT and WHY, not HOW
Can improve code quality using technique: explain what and why, not how
Comments should explain what and why aspect of the code, rather than the how aspect.
👍 What : The specification of what the code supposed to do. The reader can compare such comments to the implementation to verify if the implementation is correct
Example: This method is possibly buggy because the implementation does not seem to match the comment. In this case the comment could help the reader to detect the bug.
/** Removes all spaces from the {@code input} */
void compact(String input){
input.trim();
}
👍 Why : The rationale for the current implementation.
Example: Without this comment, the reader will not know the reason for calling this method.
// Remove spaces to comply with IE23.5 formatting rules
compact(input);
👎 How : The explanation for how the code works. This should already be apparent from the code, if the code is self-explanatory. Adding comments to explain the same thing is redundant.
Example:
Bad Reason: Comment explains how the code works.
// return true if both left end and right end are correct or the size has not incremented
return (left && right) || (input.size() == size);
Good Reason: Code refactored to be self-explanatory. Comment no longer needed.
boolean isSameSize = (input.size() == size) ;
return (isLeftEndCorrect && isRightEndCorrect) || isSameSize;
null
Documentation:
-
Update documentation to match the product.
-
Create the first version of your Project Portfolio Page (PPP). Reason: Each member needs to create a PPP to describe your contribution to the project. Creating a PPP takes a significant effort; it is too risky to leave it to the last week of the project.
Relevant: [
At the end of the project each student is required to submit a Project Portfolio Page.
-
Objective:
- For you to use (e.g. in your resume) as a well-documented data point of your SE experience
- For us to use as a data point to evaluate your,
- contributions to the project
- your documentation skills
-
Sections to include:
-
Overview: A short overview of your product to provide some context to the reader.
-
Summary of Contributions:
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
https://nuscs2113-ay1819s1.github.io/dashboard/#=undefined&search=githbub_username_in_lower_case(replacegithbub_username_in_lower_casewith your actual username in lower case e.g.,johndoe). This link is also available in the Project List Page -- linked to the icon under your photo. - Main feature implemented: A summary of the main feature you implemented
- Other contributions:
- Contributions to project management e.g., setting up project tools, managing releases, managing issue tracker etc.
- Evidence of helping others e.g. responses you posted in our forum, bugs you reported in other team's products,
- Evidence of technical leadership e.g. sharing useful information in the forum
- [Optional] Other minor enhancements: If you have other enhancements that you implemented, which are not related to your main feature, you can include it here. If you have written a significant amount of code that can be advertised as a feature by itself, but does not belong to your main feature, you can choose to include it as a part of the optional enhancements.
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
-
Contributions to the User Guide: Reproduce the parts in the User Guide that you wrote. This can include features you implemented as well as features you propose to implement.
The purpose of allowing you to include proposed features is to provide you more flexibility to show your documentation skills. e.g. you can bring in a proposed feature just to give you an opportunity to use a UML diagram type not used by the actual features. -
Contributions to the Developer Guide: Reproduce the parts in the Developer Guide that you wrote. Ensure there is enough content to evaluate your technical documentation skills and UML modelling skills. You can include descriptions of your design/implementations, possible alternatives, pros and cons of alternatives, etc.
-
If you plan to use the PPP in your Resume, you can also include your SE work outside of the module (will not be graded)
-
-
Format:
-
File name:
docs/team/githbub_username_in_lower_case.adoce.g.,docs/team/johndoe.adoc -
Follow the example in the AddressBook-Level4, but ignore the following two lines in it.
- Minor enhancement: added a history command that allows the user to navigate to previous commands using up/down keys.
- Code contributed: [Functional code] [Test code] {give links to collated code files}
-
💡 You can use the Asciidoc's
includefeature to include sections from the developer guide or the user guide in your PPP. Follow the example in the sample. -
It is assumed that all contents in the PPP were written primarily by you. If any section is written by someone else e.g. someone else wrote described the feature in the User Guide but you implemented the feature, clearly state that the section was written by someone else (e.g.
Start of Extract [from: User Guide] written by Jane Doe). Reason: Your writing skills will be evaluated based on the PPP -
Page limit: If you have more content than the limit given below, shorten (or omit some content) so that you do not exceed the page limit. Having too much content in the PPP will be viewed unfavorably during grading. Note: the page limits given below are after converting to PDF format. The actual amount of content you require is actually less than what these numbers suggest because the HTML → PDF conversion adds a lot of spacing around content.
Content Limit Overview + Summary of contributions 0.5-1 Contributions to the User Guide 1-3 Contributions to the Developer Guide 3-6 Total 5-10
-
Demo:
- Do a product demo to serve as a rehearsal for the final project demo at v1.4
- Follow
final demo instructions as much as possible. - Cover all features, not just the ones added in the recent iteration.
- Try to make it a 'well prepared' demo i.e., know in advance exactly what you'll do in the demo.
- Follow
-
Duration: Strictly
(teamSize x 3.5) + 1minutes e.g. 19 minutes for a 5-person team. Exceeding this limit will be penalized. The extra minute is for the first speaker to give an overview of the product. -
Target audience: Assume you are giving a demo to a higher-level manager of your company, to brief him/her on the current capabilities of the product. This is the first time they are seeing the new product you developed but they are familiar with the AddressBook-level4 (AB4) product.
-
Scope:
- Each person should demo the enhancements they added. However, it's ok for one member to do all the typing.
- Subjected to the constraint mentioned in the previous point, as far as possible, organize the demo to present a cohesive picture of the product as a whole, presented in a logical order. Remember to explain the target user profile and value proposition early in the demo.
- It is recommended you showcase how the feature improves the user’s life rather than simply describe each feature.
- No need to cover design/implementation details as the manager is not interested in those details.
- Mention features you inherited from AB4 only if they are needed to explain your new features. Reason: existing features will not earn you marks, and the audience is already familiar with AB4 features.
-
Structure:
- Demo the product using the same executable you submitted, on your own laptop, using the TV.
- It can be a sitting down demo: You'll be demonstrating the features using the TV while sitting down. But you may stand around the TV if you prefer that way.
- It will be uninterrupted demo: The audience members will not interrupt you during the demo. That means you should finish within the given time.
- The app should be populated with a significant amount of
realistic data at the start. e.g at least 20 contacts. Trying to demo a product using just 1-2 sample data creates a bad impression. - Dress code : The level of formality is up to you, but it is recommended that the whole team dress at the same level. However, do avoid running shorts and flip-flops!
-
Optimizing the time:
- Spend as much time as possible on demonstrating the actual product. Not recommended to use slides (if you do, use them sparingly) or videos or lengthy narrations.
Avoid skits, re-enactments, dramatizations etc. This is not a sales pitch or an informercial. While you need to show how a user use the product to get value, but you don’t need to act like an imaginary user. For example, [Instead of this]Jim get’s a call from boss. "Ring ring", "hello", "oh hi Jim, can we postpone the meeting?" "Sure". Jim hang up and curses the boss under his breath. Now he starts typing ..etc.[do this]If Jim needs to postpone the meeting, he can type …It’s not that dramatization is bad or we don’t like it. We simply don’t have enough time for it.
Note that CS2101 demo requirements may differ. Different context → Different requirements. - Rehearse the steps well and ensure you can do a smooth demo. Poor quality demos can affect your grade.
- Don’t waste time repeating things the target audience already knows. e.g. no need to say things like "We are students from NUS, SoC".
- Bring sufficient amount of sample data and know how to load them to the system. You should not plan to type all the sample data during the demo itself.
- Plan the demo to be in sync with the impression you want to create. For example, if you are trying to convince that the product is easy to use, show the easiest way to perform a task before you show the full command with all the bells and whistles.
- Limit the demo to CLI inputs only. Do not explain GUI inputs because they don't earn marks.
- Spend as much time as possible on demonstrating the actual product. Not recommended to use slides (if you do, use them sparingly) or videos or lengthy narrations.
Design
W12.1 Can apply some more design patterns
W12.1a Can explain the Model View Controller (MVC) design pattern
Design → Design Patterns → MVC Pattern →
What
Context
Most applications support storage/retrieval of information, displaying of information to the user (often via multiple UIs having different formats), and changing stored information based on external inputs.
Problem
To reduce coupling resulting from the interlinked nature of the features described above.
Solution
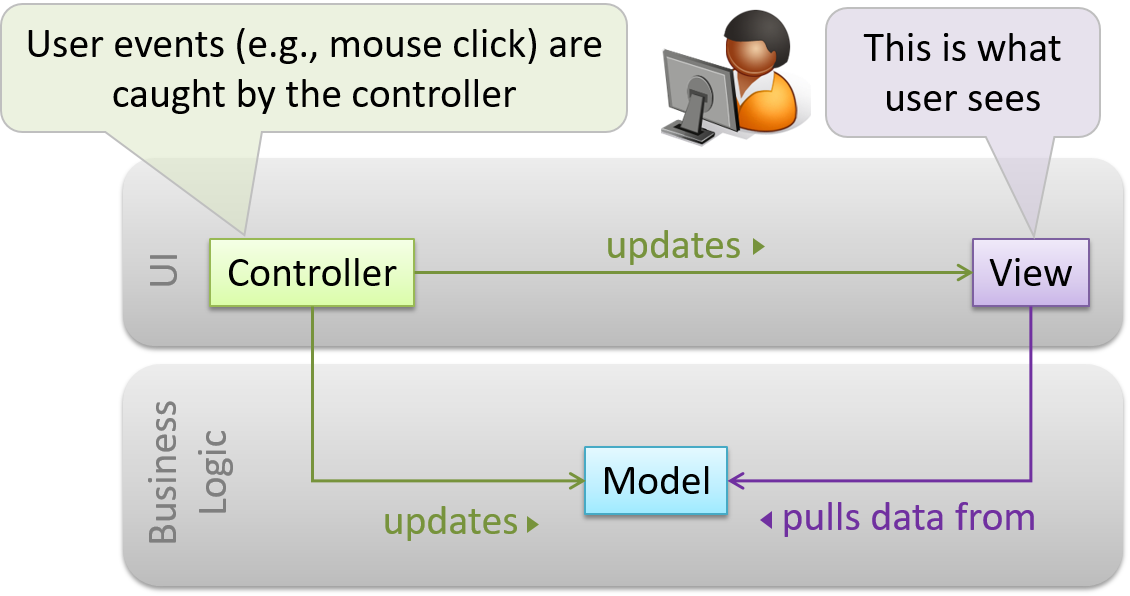
To decouple data, presentation, and control logic of an application by separating them into three different components: Model, View and Controller.
- View: Displays data, interacts with the user, and pulls data from the model if necessary.
- Controller: Detects UI events such as mouse clicks, button pushes and takes follow up action. Updates/changes the model/view when necessary.
- Model: Stores and maintains data. Updates views if necessary.
The relationship between the components can be observed in the diagram below. Typically, the UI is the combination of view and controller.
Given below is a concrete example of MVC applied to a student management system. In this scenario, the user is retrieving data of one student.
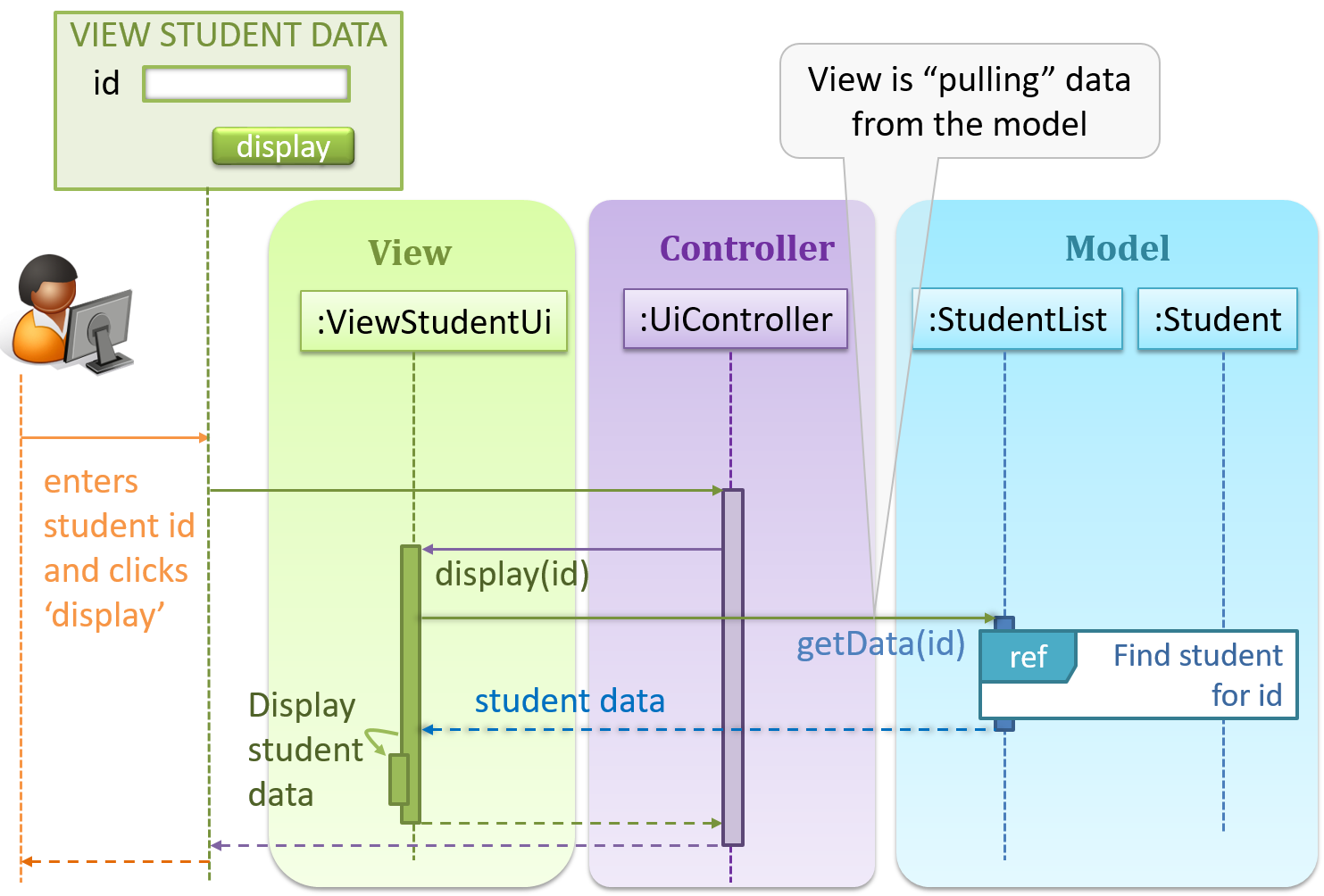
In the diagram above, when the user clicks on a button using the UI, the ‘click’ event is caught and handled by the UiController.
Note that in a simple UI where there’s only one view, Controller and View can be combined as one class.
There are many variations of the MVC model used in different domains. For example, the one used in a desktop GUI could be different from the one used in a Web application.
Evidence:
Explain relevance of the pattern to the project.
W12.1b Can explain the Observer design pattern
Design → Design Patterns → Observer Pattern →
What
Here is a scenario from the a student management system where the user is adding a new student to the system.
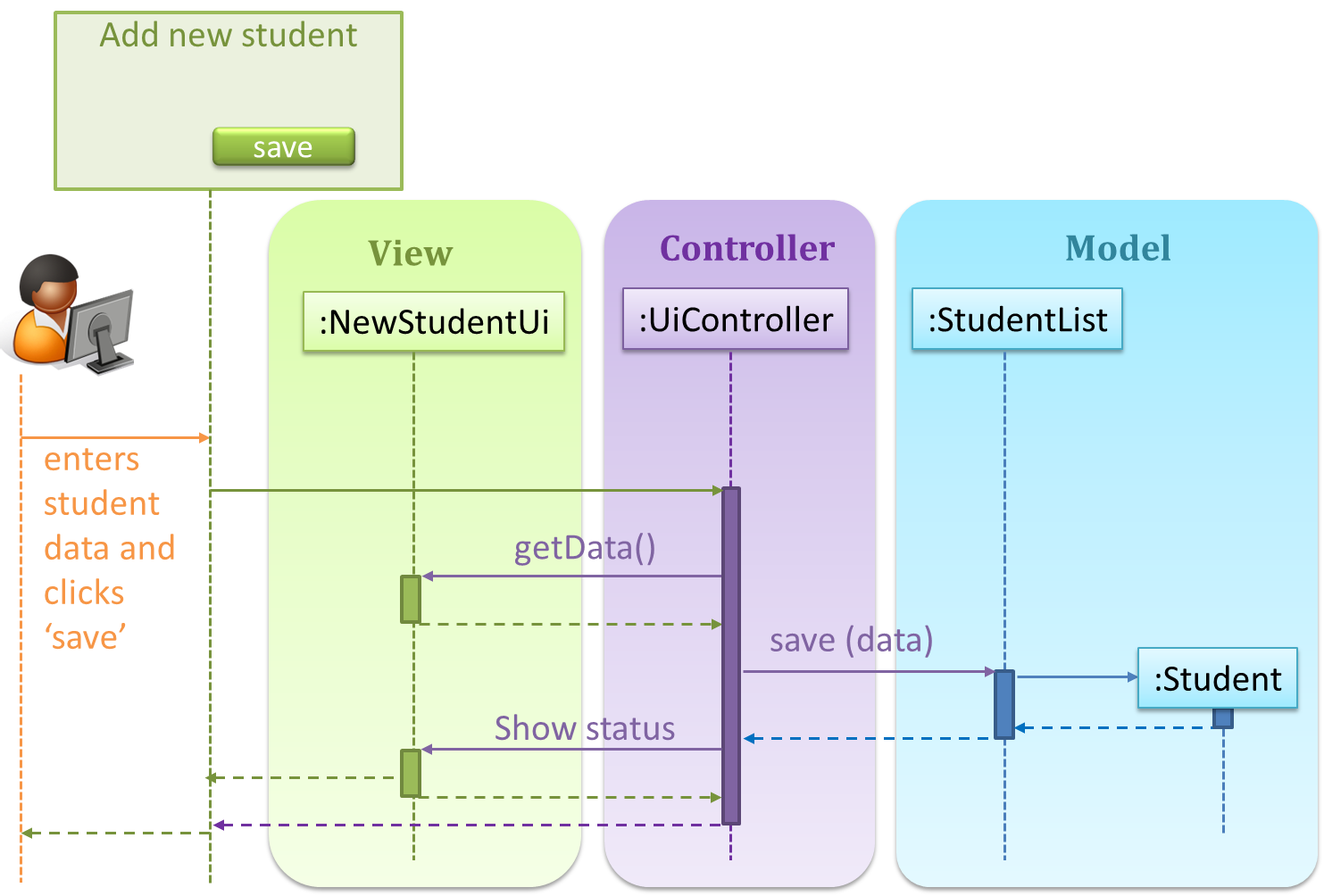
Now, assume the system has two additional views used in parallel by different users:
StudentListUi: that accesses a list of students andStudentStatsUi: that generates statistics of current students.
When a student is added to the database using NewStudentUi shown above, both StudentListUi and StudentStatsUi should get updated automatically, as shown below.
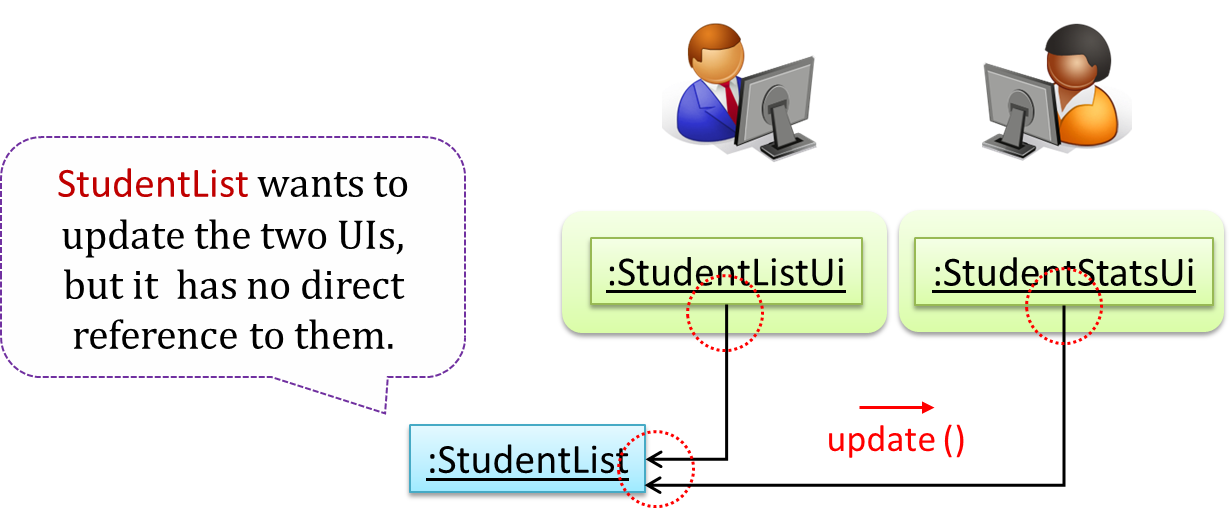
However, the StudentList object has no knowledge about StudentListUi and StudentStatsUi (note the direction of the navigability) and has no way to inform those objects. This is an example
of the type of problem addressed by the Observer pattern.
Context
An object (possibly, more than one) is interested to get notified when a change happens to another object. That is, some objects want to ‘observe’ another object.
Problem
The ‘observed’ object does not want to be coupled to objects that are ‘observing’ it.
Solution
Force the communication through an interface known to both parties.
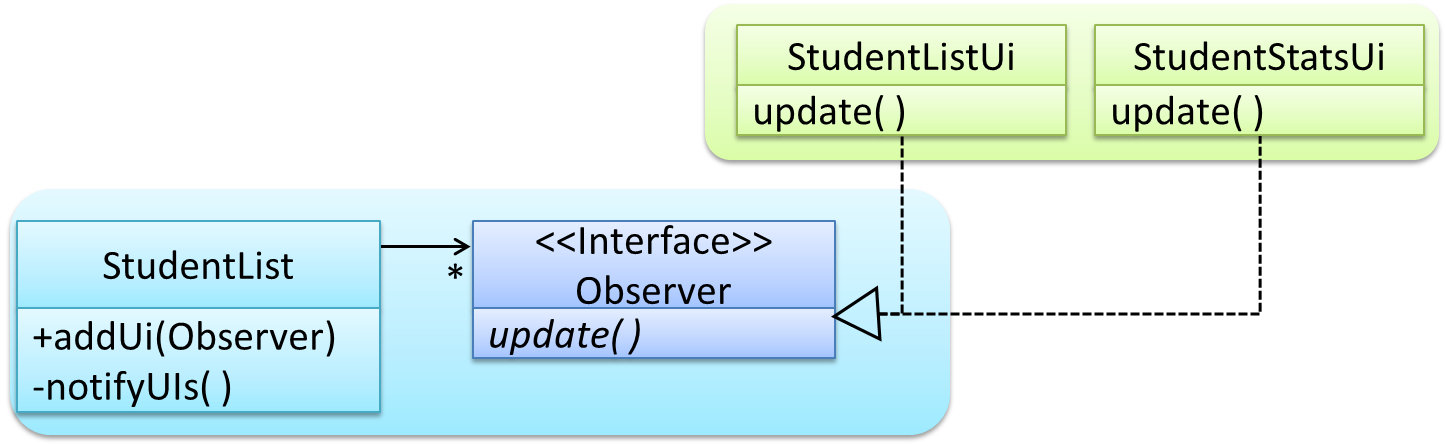
Here is the Observer pattern applied to the student management system.
During initialization of the system,
- First, create the relevant objects.
StudentList studentList = new StudentList();
StudentListUi listUi = new StudentListUi();
StudentStatusUi statusUi = new StudentStatsUi();
- Next, the two UIs indicate to the
StudentListthat they are interested in being updated wheneverStudentListchanges. This is also known as ‘subscribing for updates’.
studentList.addUi(listUi);
studentList.addUi(statusUi);
Within the addUi operation of StudentList, all Observer objects subscribers are added to an internal data structure called observerList.
//StudentList class
public void addUi(Observer o) {
observerList.add(o);
}
As such, whenever the data in StudentList changes (e.g. when a new student is added to the StudentList), all interested observers are updated by calling the notifyUIs operation.
//StudentList class
public void notifyUIs() {
for(Observer o: observerList) //for each observer in the list
o.update();
}
UIs can then pull data from the StudentList whenever the update operation is called.
//StudentListUI class
public void update() {
//refresh UI by pulling data from StudentList
}
Note that StudentList is unaware of the exact nature of the two UIs but still manages to communicate with them via an intermediary.
Here is the generic description of the observer pattern:

<< Observer >>is an interface: any class that implements it can observe an<< Observable >>. Any number of<< Observer >>objects can observe (i.e. listen to changes of) the<< Observable >>object.- The
<< Observable >>maintains a list of<< Observer >>objects.addObserver(Observer)operation adds a new<< Observer >>to the list of<< Observer >>s. - Whenever there is a change in the
<< Observable >>, thenotifyObservers()operation is called that will call theupdate()operation of all<< Observer >>sin the list.
In a GUI application, how is the Controller notified when the “save” button is clicked? UI frameworks such as JavaFX has inbuilt support for the Observer pattern.
Explain how polymorphism is used in the Observer pattern.

With respect to the general form of the Observer pattern given above, when the Observable object invokes the notifyObservers() method, it is treating all ConcreteObserver objects as a general
type called Observer and calling the update() method of each of them. However, the update() method of each ConcreteObserver could potentially show different
behavior based on its actual type. That is, update() method shows polymorphic behavior.
In the example given below, the notifyUIs operation can result in StudentListUi and StudentStatsUi changing their views in two different ways.
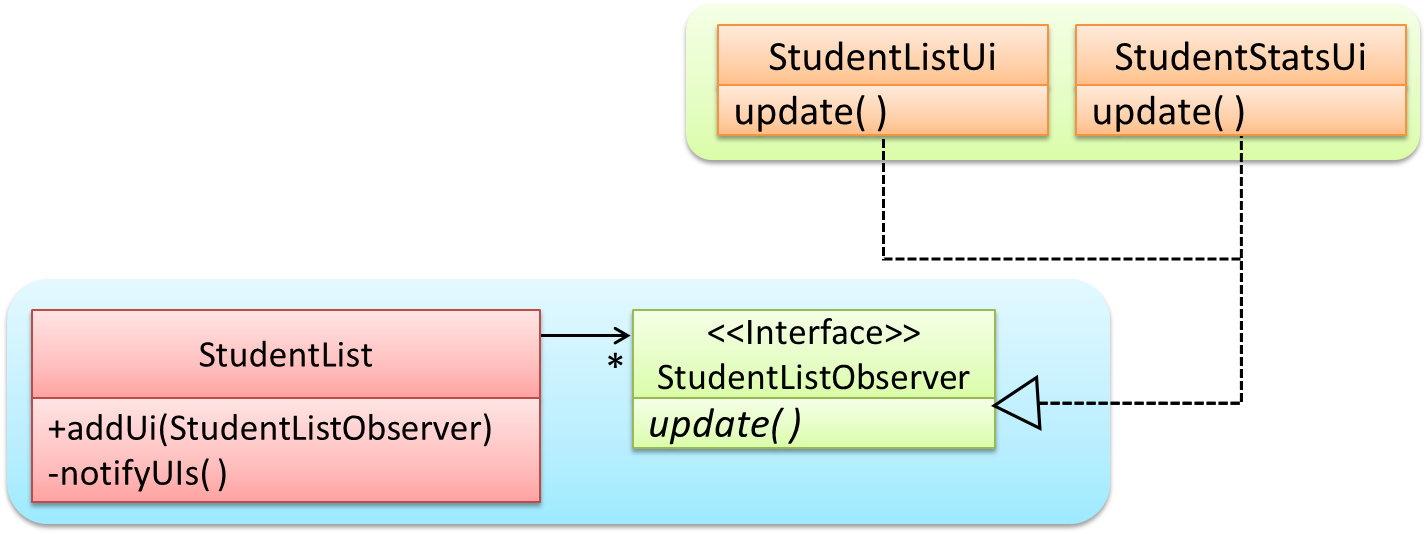
The Observer pattern can be used when we want one object to initiate an activity in another object without having a direct dependency from the first object to the second object.
True
Explanation: Yes. For example, when applying the Observer pattern to an MVC structure, Views can get notified and update themselves about a change to the Model without the Model having to depend on the Views.
Evidence:
Explain relevance of the pattern to the project.
W12.1c Can explain the Abstraction Occurrence design pattern
Design → Design Patterns → Abstraction Occurrence Pattern →
What
Context
There is a group of similar entities that appears to be ‘occurrences’ (or ‘copies’) of the same thing, sharing lots of common information, but also differing in significant ways.
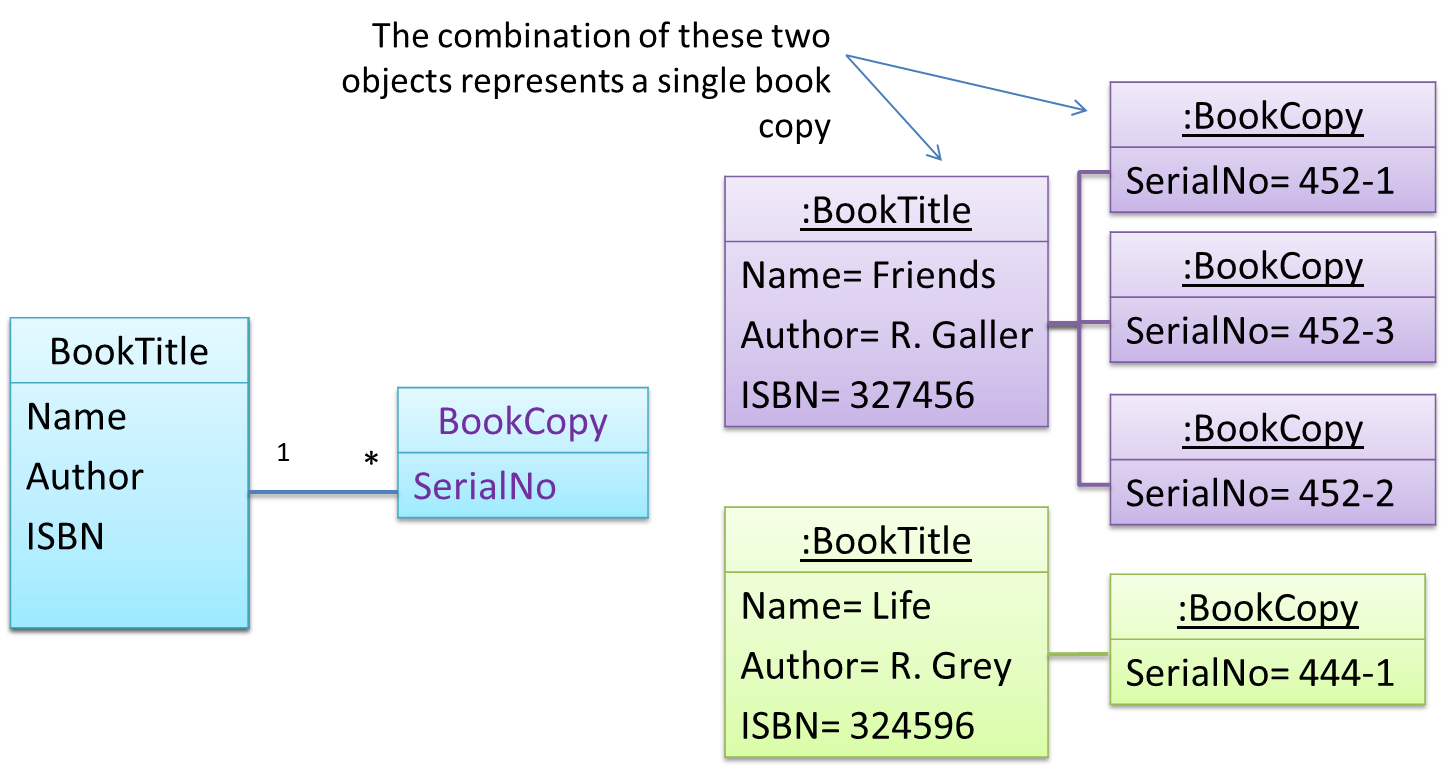
In a library, there can be multiple copies of same book title. Each copy shares common information such as book title, author, ISBN etc. However, there are also significant differences like purchase date and barcode number (assumed to be unique for each copy of the book).
Other examples:
- Episodes of the same TV series
- Stock items of the same product model (e.g. TV sets of the same model).
Problem
Representing the objects mentioned previously as a single class would be problematic because it results in duplication of data which can lead to inconsistencies in data (if some of the duplicates are not updated consistently).
Take for example the problem of representing books in a library. Assume that there could be multiple copies of the same title, bearing the same ISBN number, but different serial numbers.

The above solution requires common information to be duplicated by all instances. This will not only waste storage space, but also creates a consistency problem. Suppose that after creating several copies of the same title, the librarian realized that the author name was wrongly spelt. To correct this mistake, the system needs to go through every copy of the same title to make the correction. Also, if a new copy of the title is added later on, the librarian (or the system) has to make sure that all information entered is the same as the existing copies to avoid inconsistency.
Anti-pattern
Refer to the same Library example given above.
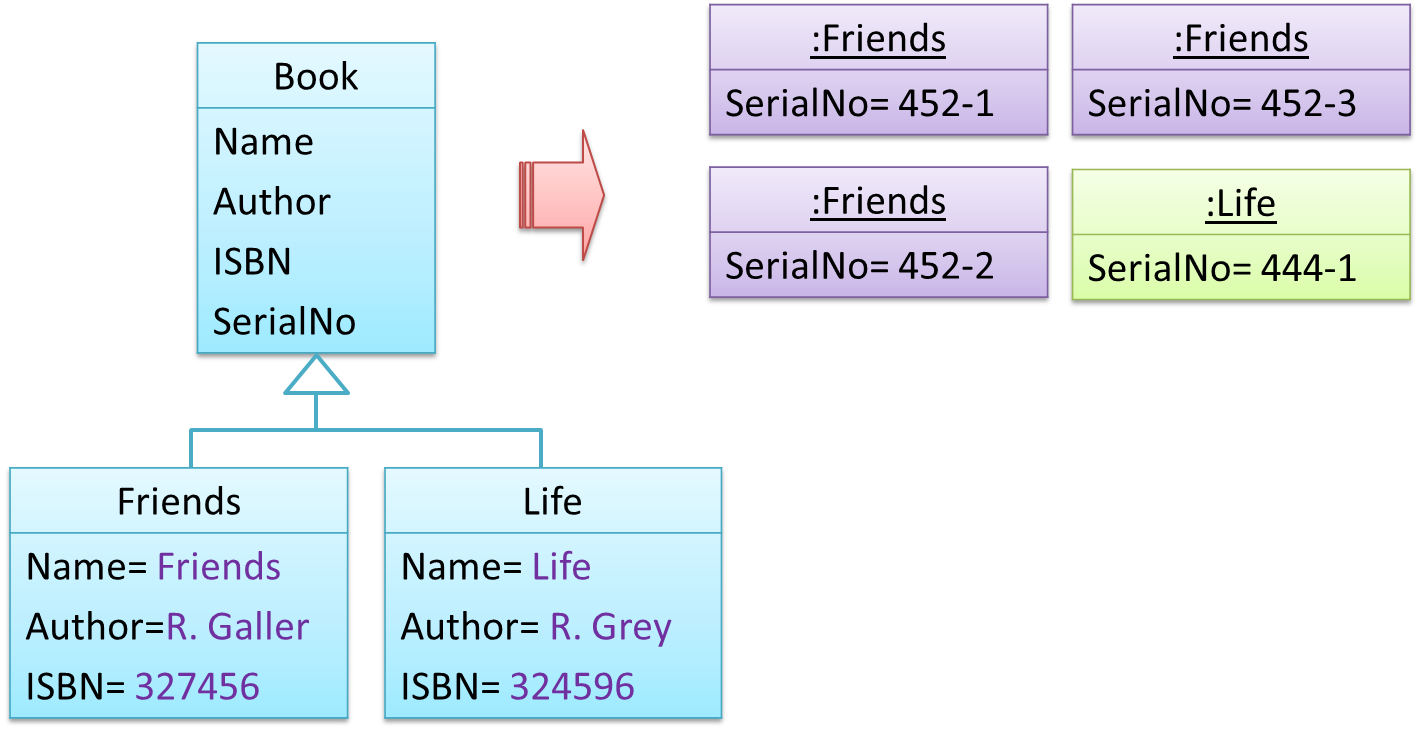
The design above segregates the common and unique information into a class hierarchy. Each book title is represented by a separate class with common data (i.e. Name, Author, ISBN) hard-coded in the class itself. This solution is problematic because each book title is represented as a class, resulting in thousands of classes (one for each title). Every time the library buys new books, the source code of the system will have to be updated with new classes.
Solution
Let a copy of an entity (e.g. a copy of a book)be represented by two objects instead of one, separating the common and unique information into two classes to avoid duplication.
Given below is how the pattern is applied to the Library example:
Here's a more generic example:
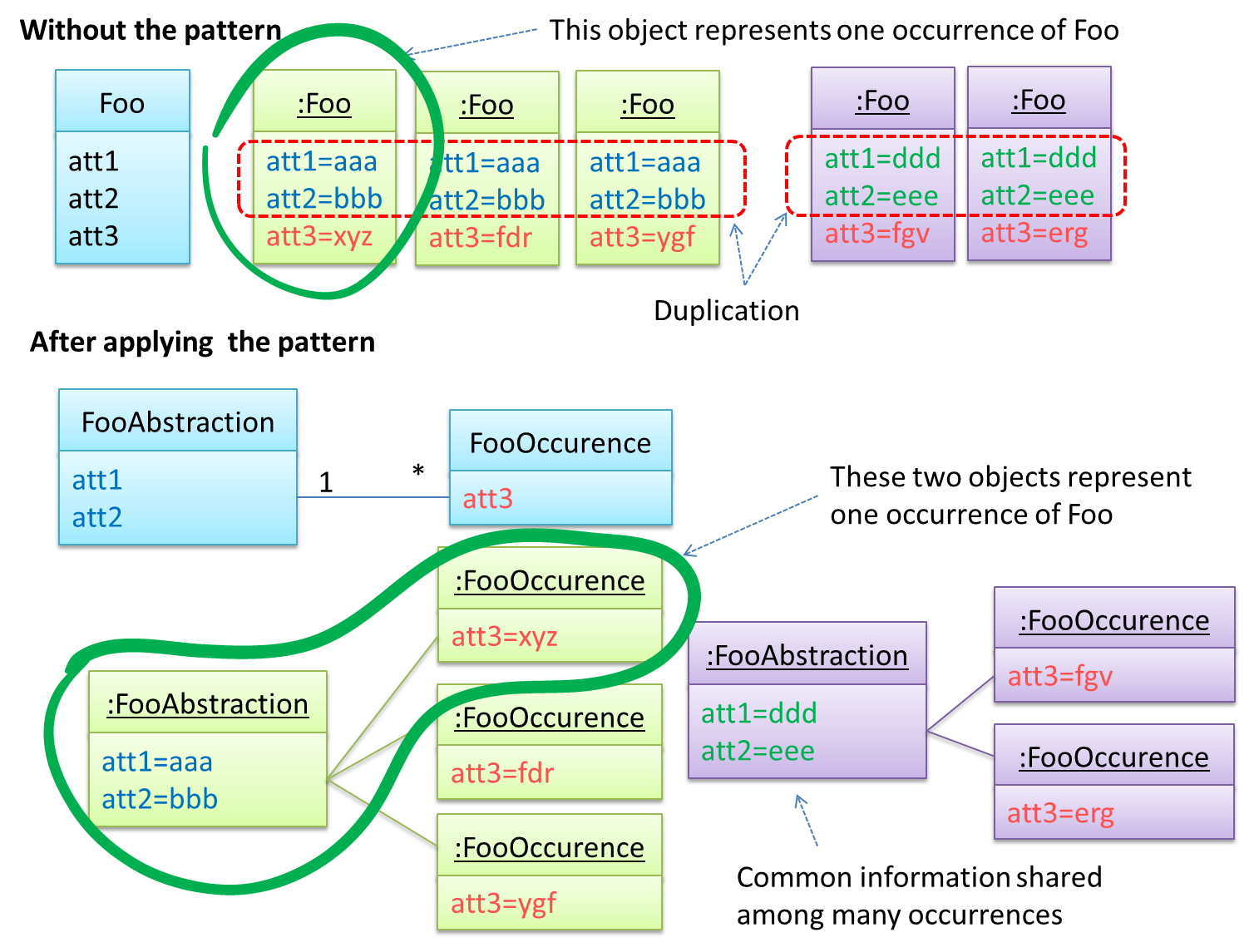
The general solution:
The << Abstraction >> class should hold all common information, and the unique information should be kept by the << Occurrence >> class. Note that ‘Abstraction’ and ‘Occurrence’
are not class names, but roles played by each class. Think of this diagram as a meta-model (i.e. a ‘model of a model’) of the BookTitle-BookCopy class diagram given above.
Which pairs of classes are likely to be the << Abstraction >> and the << Occurrence >> of the abstraction occurrence pattern?
- CarModel, Car. (Here CarModel represents a particular model of a car produced by the car manufacturer. E.g. BMW R4300)
- Car, Wheel
- Club, Member
- TeamLeader, TeamMember
- Magazine (E.g. ReadersDigest, PCWorld), MagazineIssue
One of the key things to keep in mind is that the << Abstraction >> does not represent a real entity. Rather, it represents some information common to a set of objects. A single real entity
is represented by an object of << Abstraction >> type and << Occurrence >> type.
Before applying the pattern, some attributes have the same values for multiple objects. For example, w.r.t. the BookTitle-BookCopy example given in this handout, values of attributes such as book_title,
ISBN are exactly the same for copies of the same book.
After applying the pattern, the Abstraction and the Occurrence classes together represent one entity. It is like one class has been split into two. For example, a BookTitle object and a BookCopy object combines to represent an actual Book.
- CarModel, Car: Yes
- Car, Wheel: No. Wheel is a ‘part of’ Car. A wheel is not an occurrence of Car.
- Club, Member: No. this is a ‘part of’ relationship.
- TeamLeader, TeamMember: No. A TeamMember is not an occurrence of a TeamLeader or vice versa.
- Magazine, MagazineIssue: Yes.
Which one of these is most suited for an application of the Abstraction Occurrence pattern?
(a)
Explanation:
(a) Stagings of a drama are ‘occurrences’ of the drama. They have many attributes common (e.g., Drama name, producer, cast, etc.) but some attributes are different (e.g., venue, time).
(b) Students are not occurrences of a Teacher or vice versa
(c) Module, Exam, Assignment are distinct entities with associations among them. But none of them can be considered an occurrence of another.
Evidence:
Explain relevance of the pattern to the project.
W12.1d Can recognize some of the GoF design patterns
Design → Design Patterns →
Other Design Patterns
The most famous source of design patterns is the "Gang of Four" (GoF) book which contains 23 design patterns divided into three categories:
- Creational: About object creation. They separate the operation of an application from how its objects are created.
- Abstract Factory, Builder, Factory Method, Prototype, Singleton
- Structural: About the composition of objects into larger structures while catering for future extension in structure.
- Adapter, Bridge, Composite, Decorator, Façade, Flyweight, Proxy
- Behavioral: Defining how objects interact and how responsibility is distributed among them.
- Chain of Responsibility, Command, Interpreter, Template Method, Iterator, Mediator, Memento, Observer, State, Strategy, Visitor
Evidence:
Name a few GoF patterns not covered in the module.
W12.2 Can optimize the use of design patterns
W12.2a Can combine multiple patterns to fit a context
Design → Design Patterns →
Combining Design Patterns
Design patterns are usually embedded in a larger design and sometimes applied in combination with other design patterns.
Let us look at a case study that shows how design patterns are used in the design of a class structure for a Stock Inventory System (SIS) for a shop. The shop sells appliances, and accessories for the appliances. SIS simply stores information about each item in the store.
Use Cases:
- Create a new item
- View information about an item
- Modify information about an item
- View all available accessories for a given appliance
- List all items in the store
SIS can be accessed using multiple terminals. Shop assistants use their own terminals to access SIS, while the shop manager’s terminal continuously displays a list of all items in store. In the future, it is expected that suppliers of items use their own applications to connect to SIS to get real-time information about current stock status. User authentication is not required for the current version, but may be required in the future.
A step by step explanation of the design is given below. Note that this is one out of many possible designs. Design patterns are also applied where appropriate.
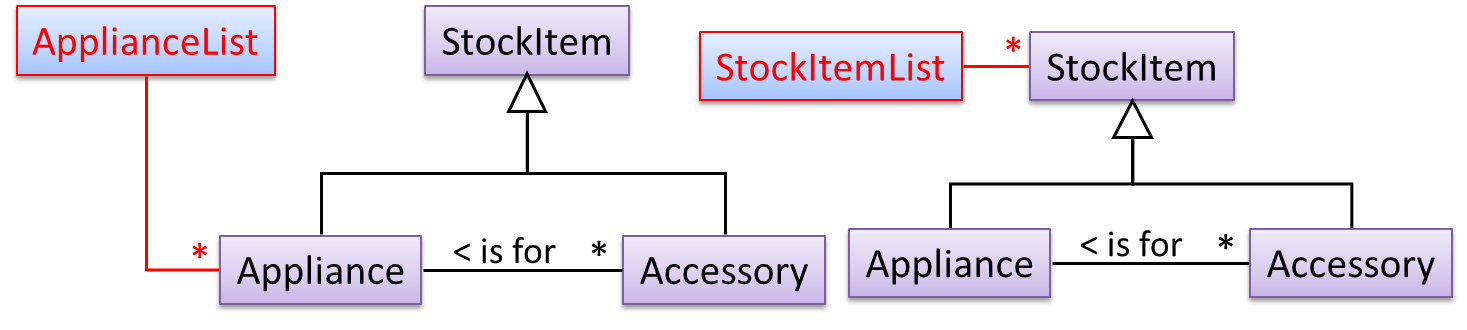
A StockItem can be an Appliance or an Accessory.
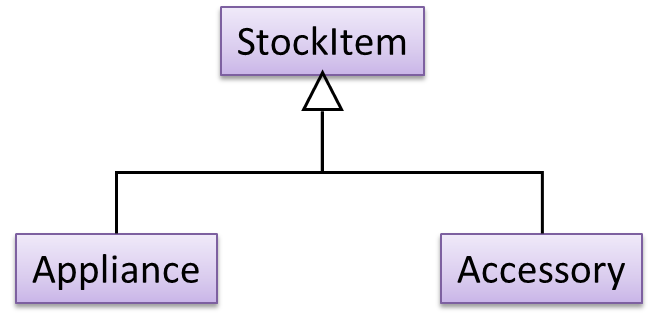
To track that each Accessory is associated with the correct Appliance, consider the following alternative class structures.
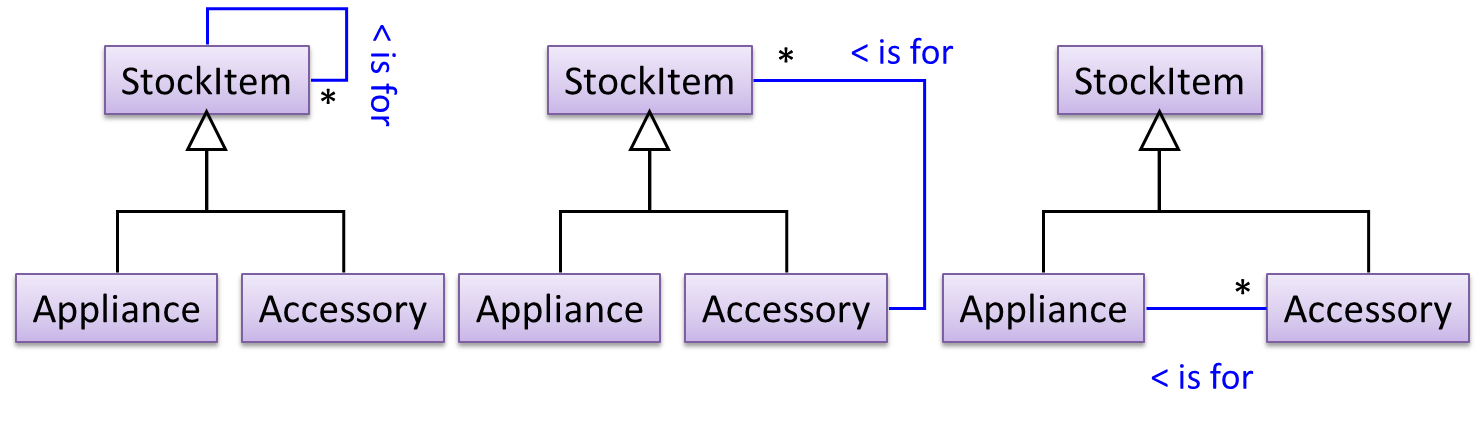
The third one seems more appropriate (the second one is suitable if accessories can have accessories). Next, consider between keeping a list of Appliances, and a list of StockItems. Which is more
appropriate?
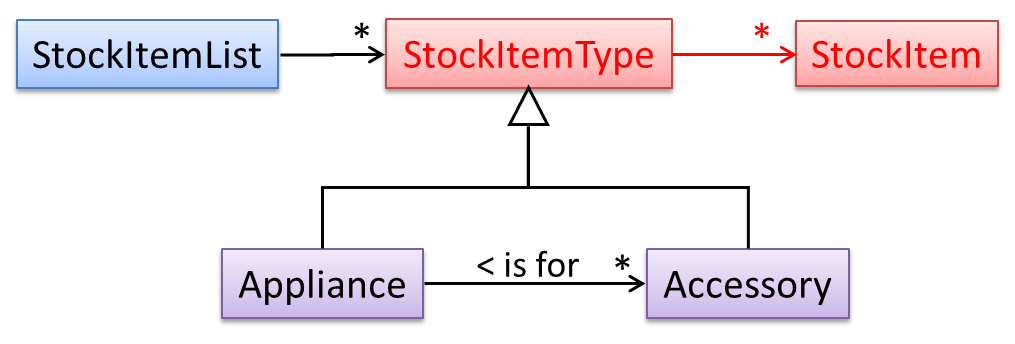
The latter seems more suitable because it can handle both appliances and accessories the same way. Next, an abstraction occurrence pattern is applied to keep track of StockItems.
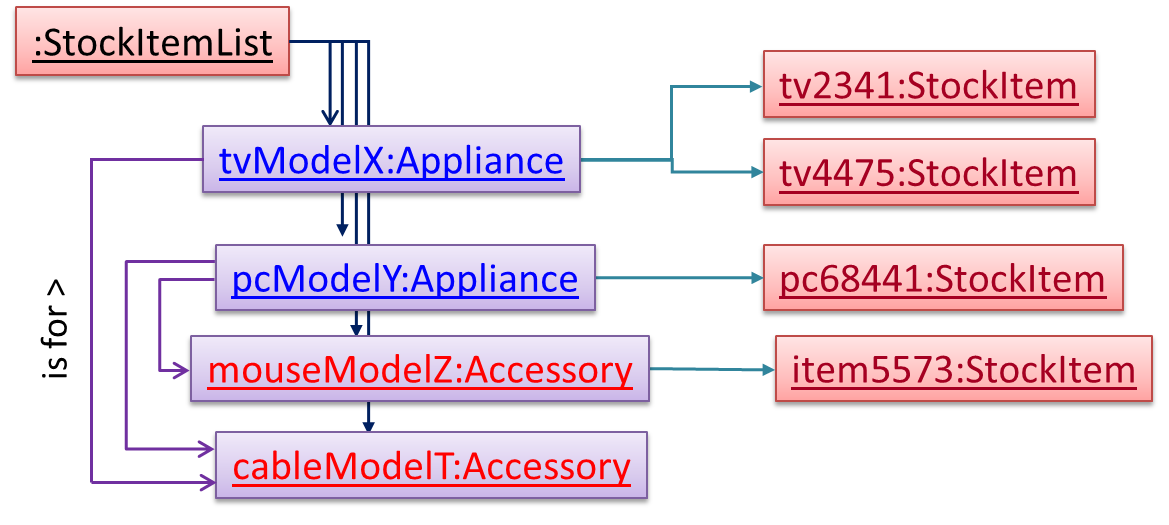
Note the inclusion of navigabilities. Here’s a sample object diagram based on the class model created thus far.
Next, apply the façade pattern to shield the SIS internals from the UI.
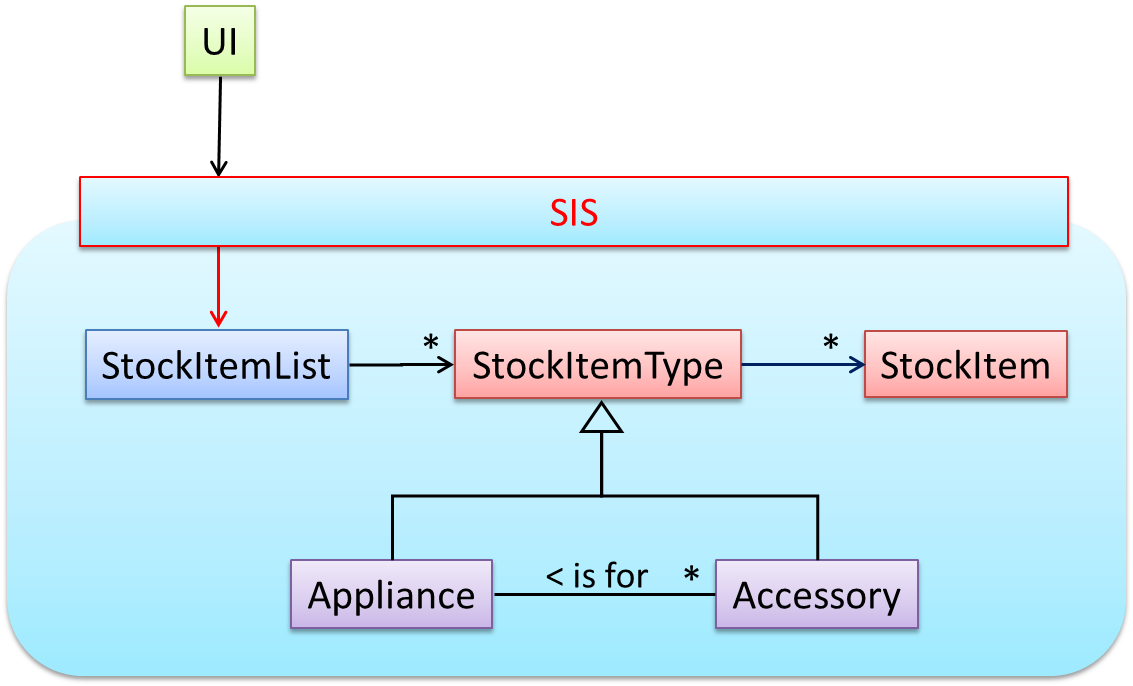
As UI consists of multiple views, the MVC pattern is applied here.
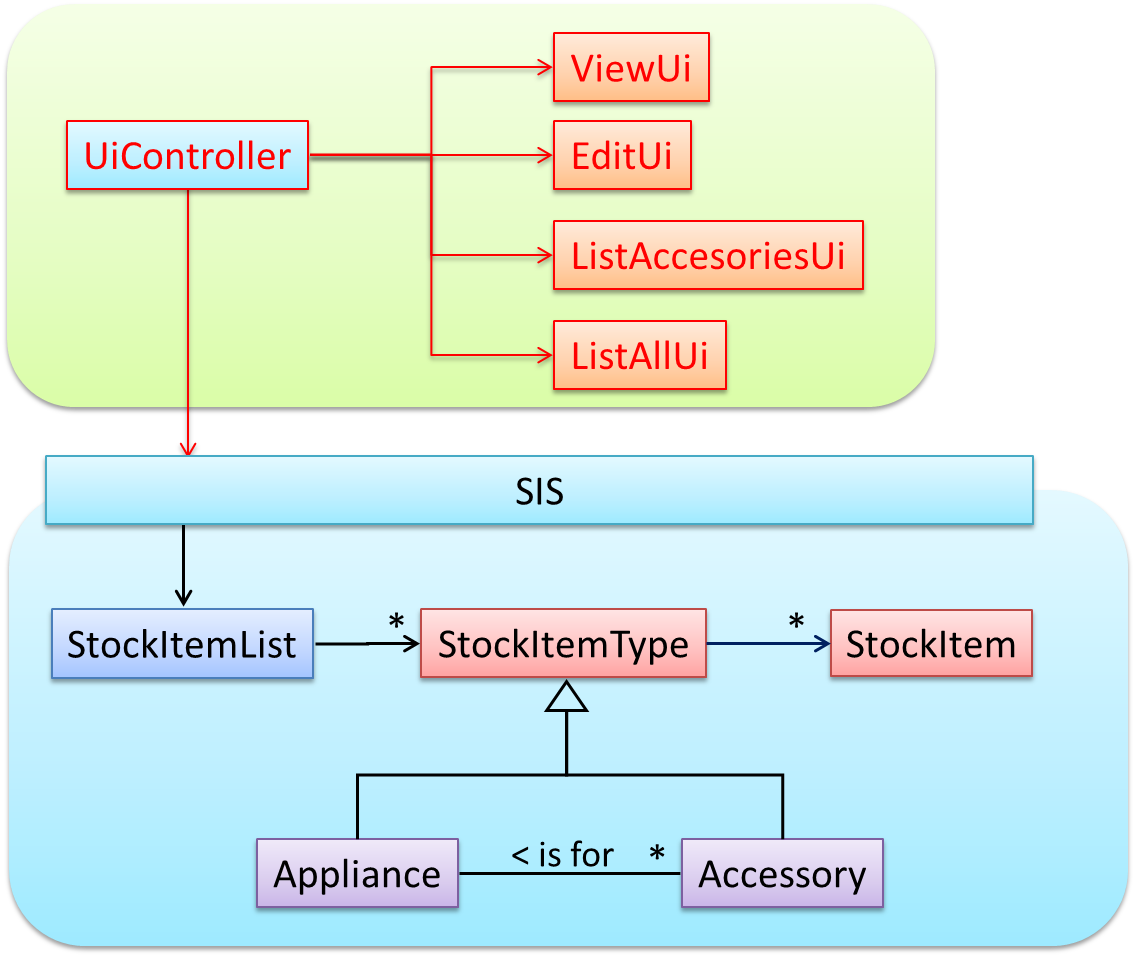
Some views need to be updated when the data change; apply the Observer pattern here.
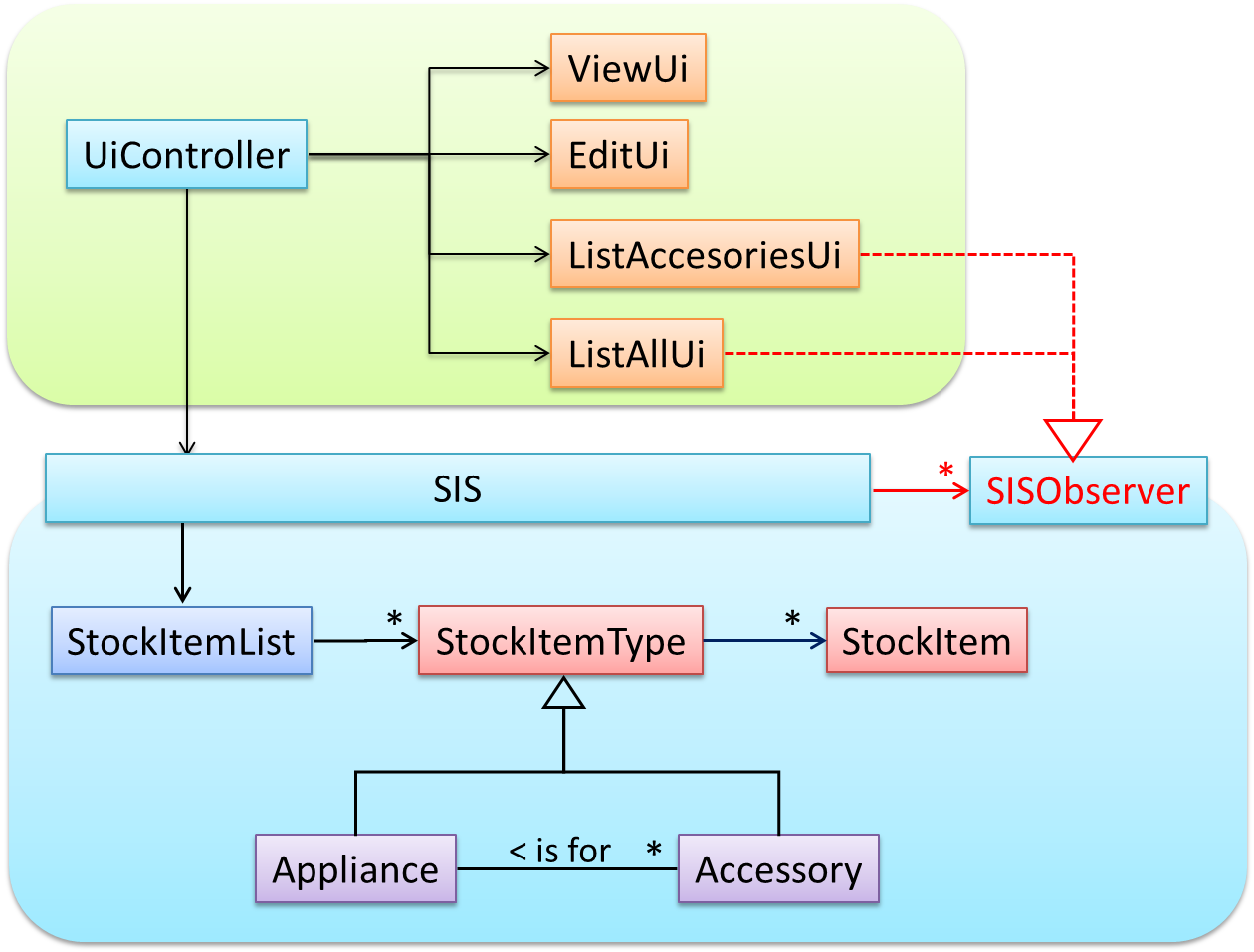
In addition, the Singleton pattern can be applied to the façade class.
Evidence:
Give an example of combining patterns.
W12.2b Can explain pros and cons of design patterns
Design → Design Patterns →
Using Design Patterns
Design pattern provides a high-level vocabulary to talk about design.
Someone can say 'apply Observer pattern here' instead of having to describe the mechanics of the solution in detail.
Knowing more patterns is a way to become more ‘experienced’. Aim to learn at least the context and the problem of patterns so that when you encounter those problems you know where to look for a solution.
Some patterns are domain-specific e.g. patterns for distributed applications, some are created in-house e.g. patterns in the company/project and some can be self-created e.g. from past experience.
Be careful not to overuse patterns. Do not throw patterns at a problem at every opportunity. Patterns come with overhead such as adding more classes or increasing the levels of abstraction. Use them only when they are needed. Before applying a pattern, make sure that:
- there is substantial improvement in the design, not just superficial.
- the associated tradeoffs are carefully considered. There are times when a design pattern is not appropriate (or an overkill).
Evidence:
Take an example patterns in the project and explain its benefits and costs.
W12.2c Can differentiate between design patterns and principles
Design → Design Patterns →
Design Patterns vs Design Principles
Design principles have varying degrees of formality – rules, opinions, rules of thumb, observations, and axioms. Compared to design patterns, principles are more general, have wider applicability, with correspondingly greater overlap among them.
W12.2d Can explain how patterns exist beyond software design domain
Design → Design Patterns →
Other Types of Patterns
The notion of capturing design ideas as "patterns" is usually attributed to Christopher Alexander. He is a building architect noted for his theories about design. His book Timeless way of building talks about "design patterns" for constructing buildings.
Here is a sample pattern from that book:
When a room has a window with a view, the window becomes a focal point: people are attracted to the window and want to look through it. The furniture in the room creates a second focal point: everyone is attracted toward whatever point the furniture aims them at (usually the center of the room or a TV). This makes people feel uncomfortable. They want to look out the window, and toward the other focus at the same time. If you rearrange the furniture, so that its focal point becomes the window, then everyone will suddenly notice that the room is much more “comfortable”
Apparently, patterns and anti-patterns are found in the field of building architecture. This is because they are general concepts applicable to any domain, not just software design. In software engineering, there are many general types of patterns: Analysis patterns, Design patterns, Testing patterns, Architectural patterns, Project management patterns, and so on.
In fact, the abstraction occurrence pattern is more of an analysis pattern than a design pattern, while MVC is more of an architectural pattern.
New patterns can be created too. If a common problem needs to be solved frequently that leads to a non-obvious and better solution, it can be formulated as a pattern so that it can be reused by others. However, don’t reinvent the wheel; the pattern might already exist.
Here are some common elements of a design pattern: Name, Context, Problem, Solution, Anti-patterns (optional), Consequences (optional), other useful information (optional).
Using similar elements, describe a pattern that is not a design pattern. It must be a pattern you have noticed, not a pattern already documented by others. You may also give a pattern not related to software.
Some examples:
- A pattern for testing textual UIs.
- A pattern for striking a good bargain at a mall such as Sim-Lim Square.
Evidence:
Give example patterns from other domains.
W12.3 Can explain some UML models
W12.3a Can explain deployment diagrams
Design → Modelling → Modelling Structure
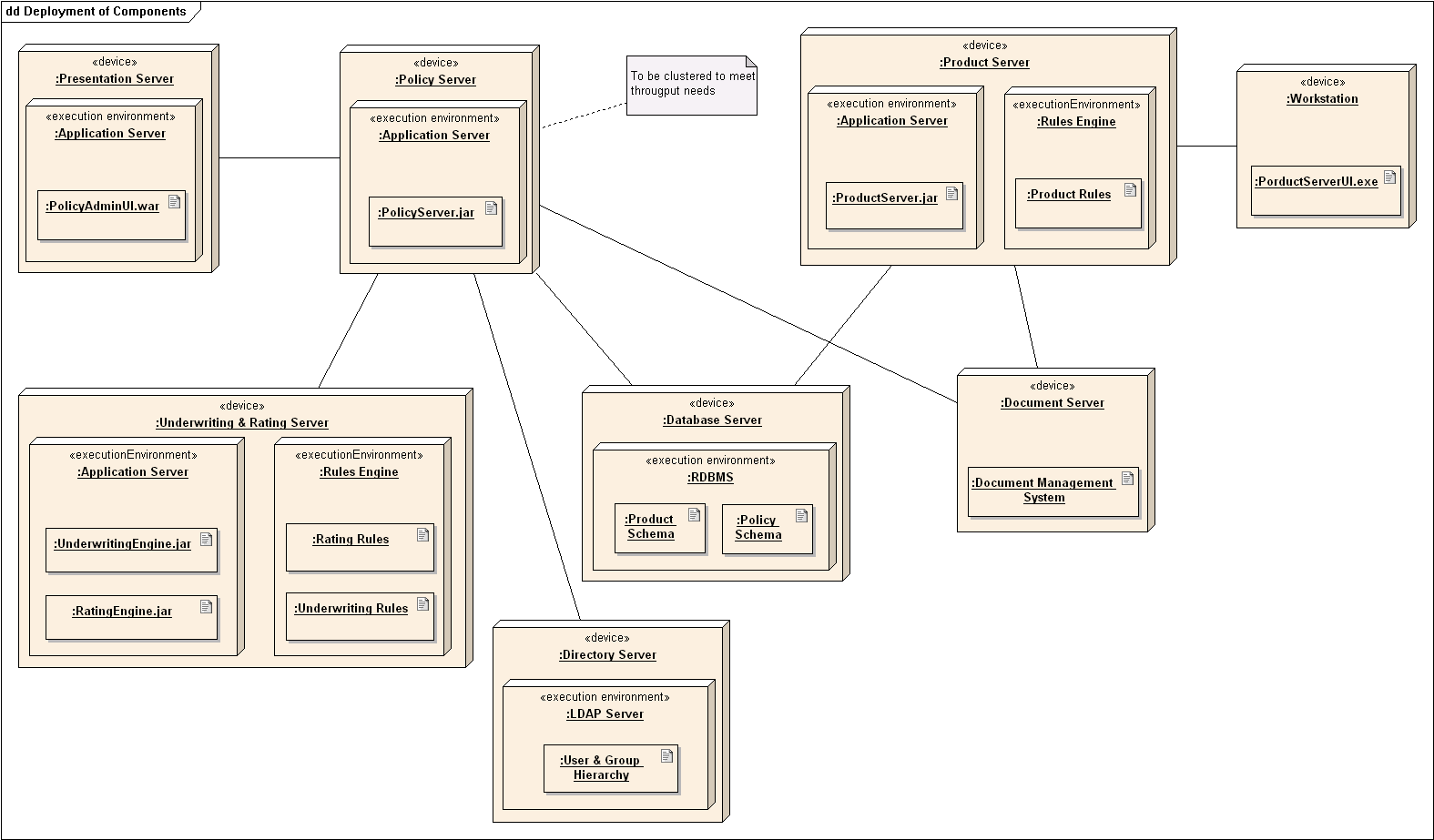
Deployment Diagrams
A deployment diagram shows a system's physical layout, revealing which pieces of software run on which pieces of hardware.
An example deployment diagram:
W12.3b Can explain component diagrams
Design → Modelling → Modelling Structure
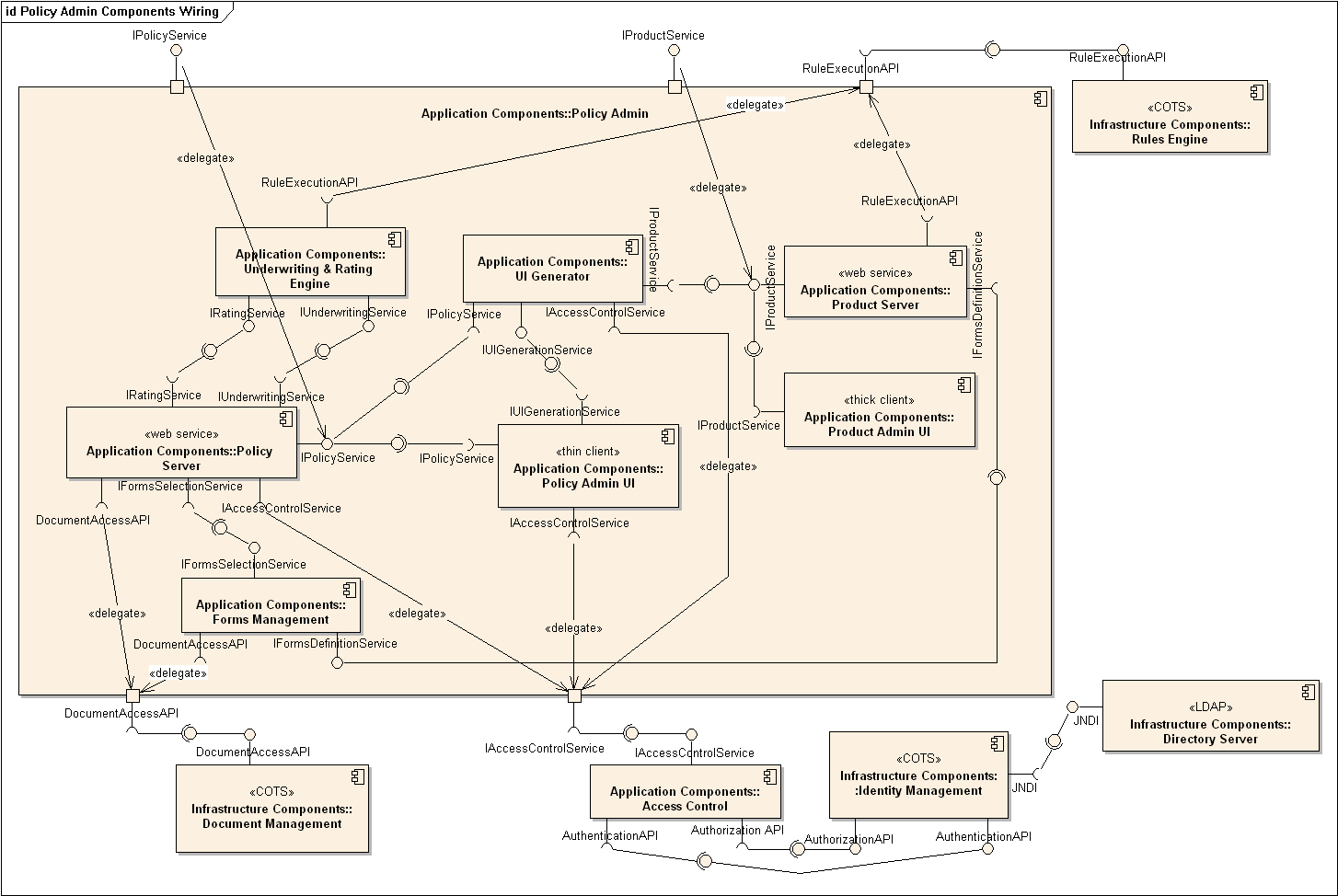
Component Diagrams
A component diagram is used to show how a system is divided into components and how they are connected to each other through interfaces.
An example component diagram:
W12.3c Can explain package diagrams
Design → Modelling → Modelling Structure
Package Diagrams
A package diagram shows packages and their dependencies. A package is a grouping construct for grouping UML elements (classes, use cases, etc.).
Here is an example package diagram:
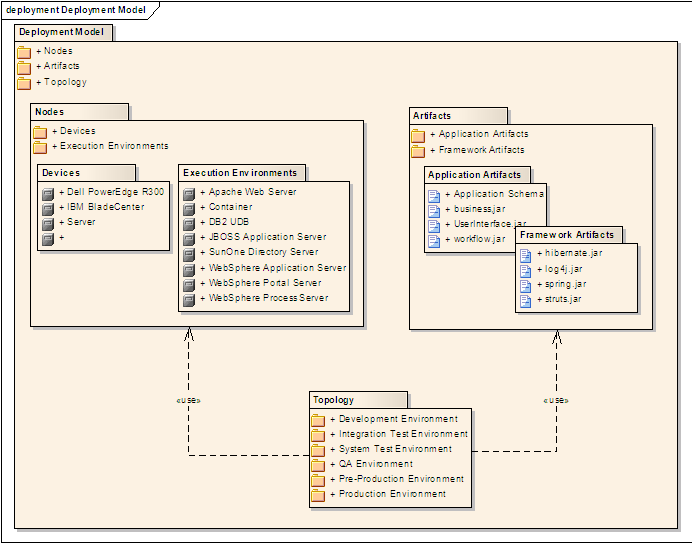
W12.3d Can explain composite structure diagrams
Design → Modelling → Modelling Structure
Composite Structure Diagrams
A composite structure diagram hierarchically decomposes a class into its internal structure.
Here is an example composite structure diagram:
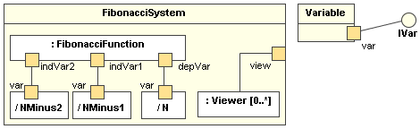
W12.3e Can explain timing diagrams
Design → Modelling → Modelling Behaviors
Timing Diagrams
A timing diagram focus on timing constraints.
Here is an example timing diagram:
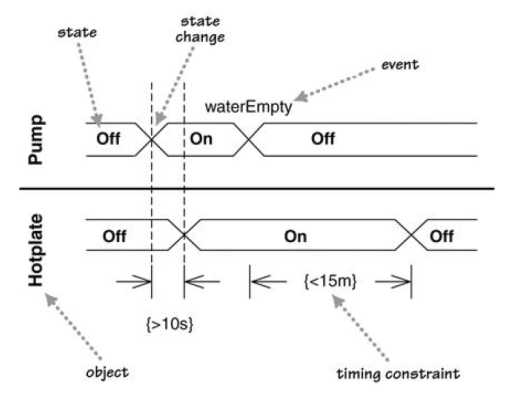
Adapted from: UML Distilled by Martin Fowler
W12.3f Can explain interaction overview diagrams
Design → Modelling → Modelling Behaviors
Interaction Overview Diagrams
An Interaction overview diagrams is a combination of activity diagrams and sequence diagrams.
An example:
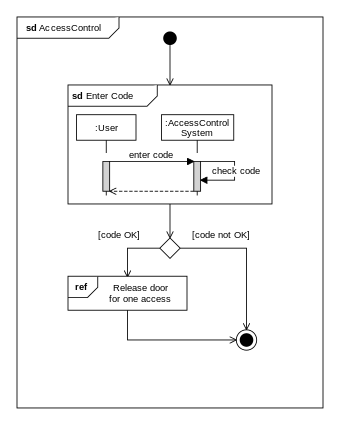
W12.3g Can explain communication diagrams
Design → Modelling → Modelling Behaviors
Communication Diagrams
A Communication diagrams are like sequence diagrams but emphasize the data links between the various participants in the interaction rather than the sequence of interactions.
An example:
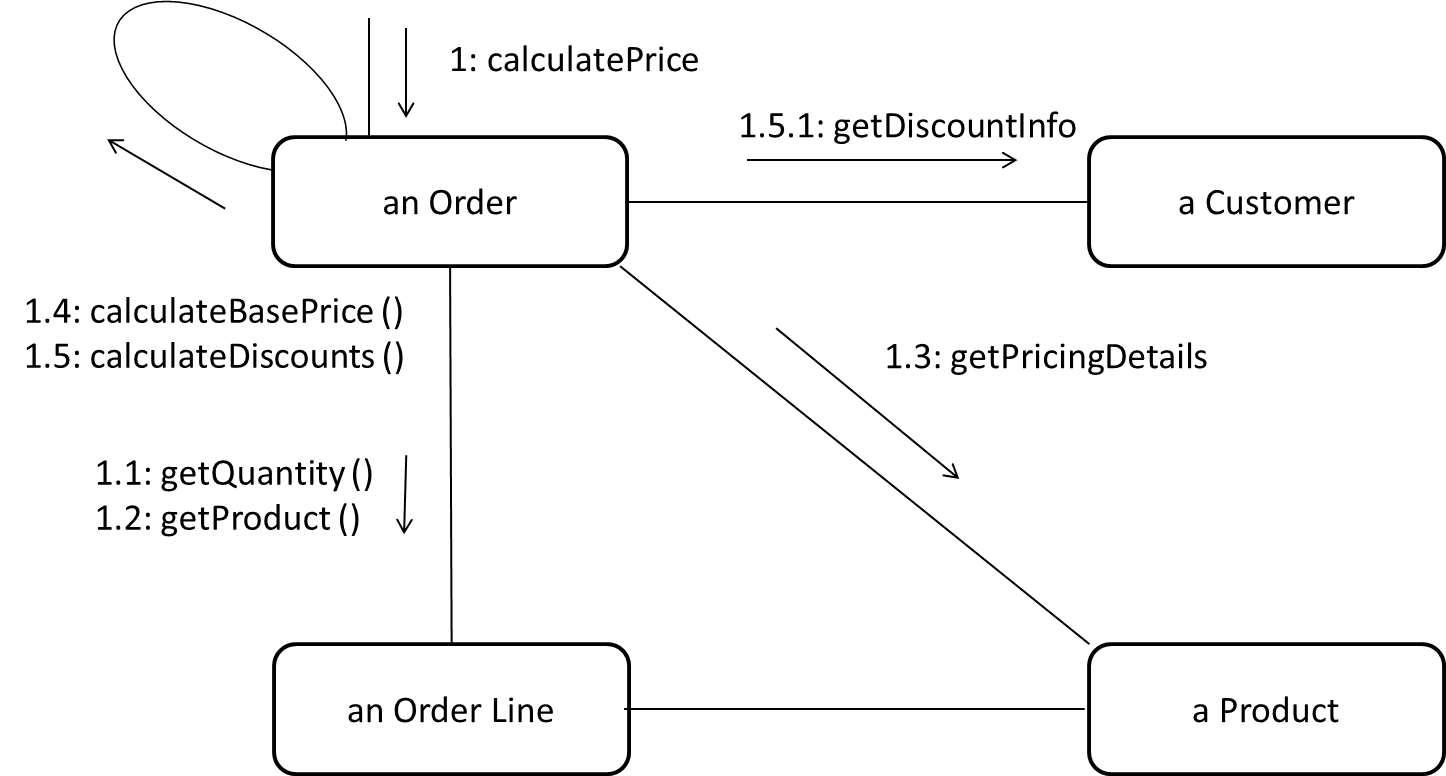
Adapted from: UML Distilled by Martin Fowler
W12.3h Can explain state machine diagrams
Design → Modelling → Modelling Behaviors
State Machine Diagrams
A State Machine Diagram models state-dependent behavior.
Consider how a CD player responds when the “eject CD” button is pushed:
- If the CD tray is already open, it does nothing.
- If the CD tray is already in the process of opening (opened half-way), it continues to open the CD tray.
- If the CD tray is closed and the CD is being played, it stops playing and opens the CD tray.
- If the CD tray is closed and CD is not being played, it simply opens the CD tray.
- If the CD tray is already in the process of closing (closed half-way), it waits until the CD tray is fully closed and opens it immediately afterwards.
What this means is that the CD player’s response to pushing the “eject CD” button depends on what it was doing at the time of the event. More generally, the CD player’s response to the event received depends on its internal state. Such a behavior is called a state-dependent behavior.
Often, state-dependent behavior displayed by an object in a system is simple enough that it needs no extra attention; such a behavior can be as simple as a conditional behavior like if x>y, then x=x-y.
Occasionally, objects may exhibit state-dependent behavior that is complex enough such that it needs to be captured into a separate model. Such state-dependent behavior can be modelled using UML state machine diagrams (SMD for short, sometimes also called ‘state charts’, ‘state diagrams’ or ‘state machines’).
An SMD views the life-cycle of an object as consisting of a finite number of states where each state displays a unique behavior pattern. An SMD captures information such as the states an object can be in, during its lifetime, and how the object responds to various events while in each state and how the object transits from one state to another. In contrast to sequence diagrams that capture object behavior one scenario at a time, SMDs capture the object’s behavior over its full life cycle.
An SMD for the Minesweeper game.
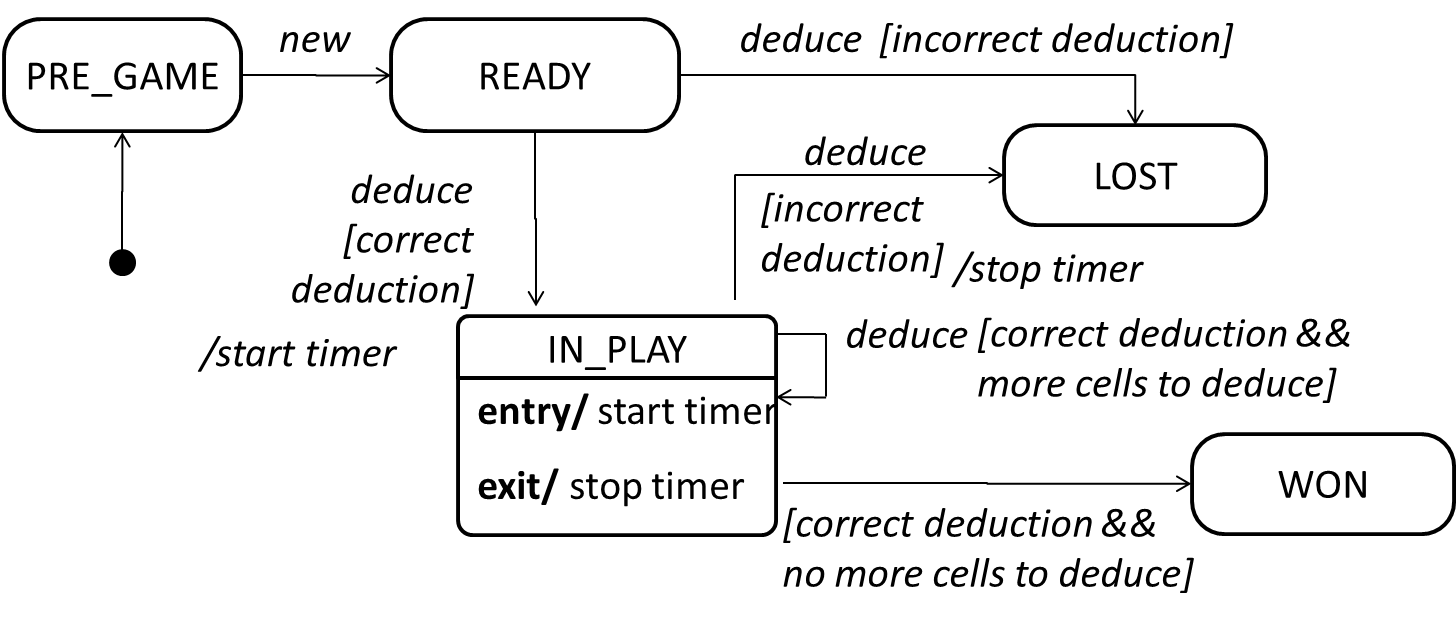
Implementation
W12.4 Can explain cloud computing basics
W12.4a Can explain cloud computing
Implementation → Reuse → Cloud Computing →
What
Cloud computing is the delivery of computing as a service over the network, rather than a product running on a local machine. This means the actual hardware and software is located at a remote location, typically, at a large server farm, while users access them over the network. Maintenance of the hardware and software is managed by the cloud provider while users typically pay for only the amount of services they use. This model is similar to the consumption of electricity; the power company manages the power plant, while the consumers pay them only for the electricity used. The cloud computing model optimizes hardware and software utilization and reduces the cost to consumers. Furthermore, users can scale up/down their utilization at will without having to upgrade their hardware and software. The traditional non-cloud model of computing is similar to everyone buying their own generators to create electricity for their own use.
W12.4b Can distinguish between IaaS, PaaS, and SaaS
Implementation → Reuse → Cloud Computing →
Iaas, PaaS, and SaaS

source:https://commons.wikimedia.org
Cloud computing can deliver computing services at three levels:
-
Infrastructure as a service (IaaS) delivers computer infrastructure as a service. For example, a user can deploy virtual servers on the cloud instead of buying physical hardware and installing server software on them. Another example would be a customer using storage space on the cloud for off-site storage of data. Rackspace is an example of an IaaS cloud provider. Amazon Elastic Compute Cloud (Amazon EC2) is another one.
-
Platform as a service (PaaS) provides a platform on which developers can build applications. Developers do not have to worry about infrastructure issues such as deploying servers or load balancing as is required when using IaaS. Those aspects are automatically taken care of by the platform. The price to pay is reduced flexibility; applications written on PaaS are limited to facilities provided by the platform. A PaaS example is the Google App Engine where developers can build applications using Java, Python, PHP, or Go whereas Amazon EC2 allows users to deploy application written in any language on their virtual servers.
-
Software as a service (SaaS) allows applications to be accessed over the network instead of installing them on a local machine. For example, Google Docs is an SaaS word processing software, while Microsoft Word is a traditional word processing software.
Google Calendar belongs to which category of cloud computing services?
- a. IaaS
- b. PaaS
- c. SaaS
(c)
Explanation: It is a software as a service. Instead of installing a calendar software on your desktop, we can use the Google Calendar software that lives ‘on the cloud’.
🅿️ Project
W12.5 Can describe a technical contribution
Covered by:
Demo
- We will do a timed demo this week as well.
- Demo your product using the latest jar file from GitHub.
- Two/three members do the demo of the entire product.
- Demo instructions given below for your reference:
W12.1a Can explain the Model View Controller
(MVC) design pattern
Design → Design Patterns → MVC Pattern →
What
Context
Most applications support storage/retrieval of information, displaying of information to the user (often via multiple UIs having different formats), and changing stored information based on external inputs.
Problem
To reduce coupling resulting from the interlinked nature of the features described above.
Solution
To decouple data, presentation, and control logic of an application by separating them into three different components: Model, View and Controller.
- View: Displays data, interacts with the user, and pulls data from the model if necessary.
- Controller: Detects UI events such as mouse clicks, button pushes and takes follow up action. Updates/changes the model/view when necessary.
- Model: Stores and maintains data. Updates views if necessary.
The relationship between the components can be observed in the diagram below. Typically, the UI is the combination of view and controller.
Given below is a concrete example of MVC applied to a student management system. In this scenario, the user is retrieving data of one student.
In the diagram above, when the user clicks on a button using the UI, the ‘click’ event is caught and handled by the UiController.
Note that in a simple UI where there’s only one view, Controller and View can be combined as one class.
There are many variations of the MVC model used in different domains. For example, the one used in a desktop GUI could be different from the one used in a Web application.
Evidence:
Explain relevance of the pattern to the project.
W12.1b Can explain the Observer design pattern
Design → Design Patterns → Observer Pattern →
What
Here is a scenario from the a student management system where the user is adding a new student to the system.
Now, assume the system has two additional views used in parallel by different users:
StudentListUi: that accesses a list of students andStudentStatsUi: that generates statistics of current students.
When a student is added to the database using NewStudentUi shown above, both StudentListUi and StudentStatsUi should get updated automatically, as shown below.
However, the StudentList object has no knowledge about StudentListUi and StudentStatsUi (note the direction of the navigability) and has no way to inform those objects. This is an example
of the type of problem addressed by the Observer pattern.
Context
An object (possibly, more than one) is interested to get notified when a change happens to another object. That is, some objects want to ‘observe’ another object.
Problem
The ‘observed’ object does not want to be coupled to objects that are ‘observing’ it.
Solution
Force the communication through an interface known to both parties.
Here is the Observer pattern applied to the student management system.
During initialization of the system,
- First, create the relevant objects.
StudentList studentList = new StudentList();
StudentListUi listUi = new StudentListUi();
StudentStatusUi statusUi = new StudentStatsUi();
- Next, the two UIs indicate to the
StudentListthat they are interested in being updated wheneverStudentListchanges. This is also known as ‘subscribing for updates’.
studentList.addUi(listUi);
studentList.addUi(statusUi);
Within the addUi operation of StudentList, all Observer objects subscribers are added to an internal data structure called observerList.
//StudentList class
public void addUi(Observer o) {
observerList.add(o);
}
As such, whenever the data in StudentList changes (e.g. when a new student is added to the StudentList), all interested observers are updated by calling the notifyUIs operation.
//StudentList class
public void notifyUIs() {
for(Observer o: observerList) //for each observer in the list
o.update();
}
UIs can then pull data from the StudentList whenever the update operation is called.
//StudentListUI class
public void update() {
//refresh UI by pulling data from StudentList
}
Note that StudentList is unaware of the exact nature of the two UIs but still manages to communicate with them via an intermediary.
Here is the generic description of the observer pattern:
<< Observer >>is an interface: any class that implements it can observe an<< Observable >>. Any number of<< Observer >>objects can observe (i.e. listen to changes of) the<< Observable >>object.- The
<< Observable >>maintains a list of<< Observer >>objects.addObserver(Observer)operation adds a new<< Observer >>to the list of<< Observer >>s. - Whenever there is a change in the
<< Observable >>, thenotifyObservers()operation is called that will call theupdate()operation of all<< Observer >>sin the list.
In a GUI application, how is the Controller notified when the “save” button is clicked? UI frameworks such as JavaFX has inbuilt support for the Observer pattern.
Explain how polymorphism is used in the Observer pattern.
With respect to the general form of the Observer pattern given above, when the Observable object invokes the notifyObservers() method, it is treating all ConcreteObserver objects as a general
type called Observer and calling the update() method of each of them. However, the update() method of each ConcreteObserver could potentially show different
behavior based on its actual type. That is, update() method shows polymorphic behavior.
In the example given below, the notifyUIs operation can result in StudentListUi and StudentStatsUi changing their views in two different ways.
The Observer pattern can be used when we want one object to initiate an activity in another object without having a direct dependency from the first object to the second object.
True
Explanation: Yes. For example, when applying the Observer pattern to an MVC structure, Views can get notified and update themselves about a change to the Model without the Model having to depend on the Views.
Evidence:
Explain relevance of the pattern to the project.
W12.1c Can explain the Abstraction Occurrence
design pattern
Design → Design Patterns → Abstraction Occurrence Pattern →
What
Context
There is a group of similar entities that appears to be ‘occurrences’ (or ‘copies’) of the same thing, sharing lots of common information, but also differing in significant ways.
In a library, there can be multiple copies of same book title. Each copy shares common information such as book title, author, ISBN etc. However, there are also significant differences like purchase date and barcode number (assumed to be unique for each copy of the book).
Other examples:
- Episodes of the same TV series
- Stock items of the same product model (e.g. TV sets of the same model).
Problem
Representing the objects mentioned previously as a single class would be problematic because it results in duplication of data which can lead to inconsistencies in data (if some of the duplicates are not updated consistently).
Take for example the problem of representing books in a library. Assume that there could be multiple copies of the same title, bearing the same ISBN number, but different serial numbers.
The above solution requires common information to be duplicated by all instances. This will not only waste storage space, but also creates a consistency problem. Suppose that after creating several copies of the same title, the librarian realized that the author name was wrongly spelt. To correct this mistake, the system needs to go through every copy of the same title to make the correction. Also, if a new copy of the title is added later on, the librarian (or the system) has to make sure that all information entered is the same as the existing copies to avoid inconsistency.
Anti-pattern
Refer to the same Library example given above.
The design above segregates the common and unique information into a class hierarchy. Each book title is represented by a separate class with common data (i.e. Name, Author, ISBN) hard-coded in the class itself. This solution is problematic because each book title is represented as a class, resulting in thousands of classes (one for each title). Every time the library buys new books, the source code of the system will have to be updated with new classes.
Solution
Let a copy of an entity (e.g. a copy of a book)be represented by two objects instead of one, separating the common and unique information into two classes to avoid duplication.
Given below is how the pattern is applied to the Library example:
Here's a more generic example:
The general solution:
The << Abstraction >> class should hold all common information, and the unique information should be kept by the << Occurrence >> class. Note that ‘Abstraction’ and ‘Occurrence’
are not class names, but roles played by each class. Think of this diagram as a meta-model (i.e. a ‘model of a model’) of the BookTitle-BookCopy class diagram given above.
Which pairs of classes are likely to be the << Abstraction >> and the << Occurrence >> of the abstraction occurrence pattern?
- CarModel, Car. (Here CarModel represents a particular model of a car produced by the car manufacturer. E.g. BMW R4300)
- Car, Wheel
- Club, Member
- TeamLeader, TeamMember
- Magazine (E.g. ReadersDigest, PCWorld), MagazineIssue
One of the key things to keep in mind is that the << Abstraction >> does not represent a real entity. Rather, it represents some information common to a set of objects. A single real entity
is represented by an object of << Abstraction >> type and << Occurrence >> type.
Before applying the pattern, some attributes have the same values for multiple objects. For example, w.r.t. the BookTitle-BookCopy example given in this handout, values of attributes such as book_title,
ISBN are exactly the same for copies of the same book.
After applying the pattern, the Abstraction and the Occurrence classes together represent one entity. It is like one class has been split into two. For example, a BookTitle object and a BookCopy object combines to represent an actual Book.
- CarModel, Car: Yes
- Car, Wheel: No. Wheel is a ‘part of’ Car. A wheel is not an occurrence of Car.
- Club, Member: No. this is a ‘part of’ relationship.
- TeamLeader, TeamMember: No. A TeamMember is not an occurrence of a TeamLeader or vice versa.
- Magazine, MagazineIssue: Yes.
Which one of these is most suited for an application of the Abstraction Occurrence pattern?
(a)
Explanation:
(a) Stagings of a drama are ‘occurrences’ of the drama. They have many attributes common (e.g., Drama name, producer, cast, etc.) but some attributes are different (e.g., venue, time).
(b) Students are not occurrences of a Teacher or vice versa
(c) Module, Exam, Assignment are distinct entities with associations among them. But none of them can be considered an occurrence of another.
Evidence:
Explain relevance of the pattern to the project.
W12.1d Can recognize some of the GoF design
patterns
Design → Design Patterns →
Other Design Patterns
The most famous source of design patterns is the "Gang of Four" (GoF) book which contains 23 design patterns divided into three categories:
- Creational: About object creation. They separate the operation of an application from how its objects are created.
- Abstract Factory, Builder, Factory Method, Prototype, Singleton
- Structural: About the composition of objects into larger structures while catering for future extension in structure.
- Adapter, Bridge, Composite, Decorator, Façade, Flyweight, Proxy
- Behavioral: Defining how objects interact and how responsibility is distributed among them.
- Chain of Responsibility, Command, Interpreter, Template Method, Iterator, Mediator, Memento, Observer, State, Strategy, Visitor
Evidence:
Name a few GoF patterns not covered in the module.
W12.2a Can combine multiple patterns to fit
a context
Design → Design Patterns →
Combining Design Patterns
Design patterns are usually embedded in a larger design and sometimes applied in combination with other design patterns.
Let us look at a case study that shows how design patterns are used in the design of a class structure for a Stock Inventory System (SIS) for a shop. The shop sells appliances, and accessories for the appliances. SIS simply stores information about each item in the store.
Use Cases:
- Create a new item
- View information about an item
- Modify information about an item
- View all available accessories for a given appliance
- List all items in the store
SIS can be accessed using multiple terminals. Shop assistants use their own terminals to access SIS, while the shop manager’s terminal continuously displays a list of all items in store. In the future, it is expected that suppliers of items use their own applications to connect to SIS to get real-time information about current stock status. User authentication is not required for the current version, but may be required in the future.
A step by step explanation of the design is given below. Note that this is one out of many possible designs. Design patterns are also applied where appropriate.
A StockItem can be an Appliance or an Accessory.
To track that each Accessory is associated with the correct Appliance, consider the following alternative class structures.
The third one seems more appropriate (the second one is suitable if accessories can have accessories). Next, consider between keeping a list of Appliances, and a list of StockItems. Which is more
appropriate?
The latter seems more suitable because it can handle both appliances and accessories the same way. Next, an abstraction occurrence pattern is applied to keep track of StockItems.
Note the inclusion of navigabilities. Here’s a sample object diagram based on the class model created thus far.
Next, apply the façade pattern to shield the SIS internals from the UI.
As UI consists of multiple views, the MVC pattern is applied here.
Some views need to be updated when the data change; apply the Observer pattern here.
In addition, the Singleton pattern can be applied to the façade class.
Evidence:
Give an example of combining patterns.
W12.2b Can explain pros and cons of design
patterns
Design → Design Patterns →
Using Design Patterns
Design pattern provides a high-level vocabulary to talk about design.
Someone can say 'apply Observer pattern here' instead of having to describe the mechanics of the solution in detail.
Knowing more patterns is a way to become more ‘experienced’. Aim to learn at least the context and the problem of patterns so that when you encounter those problems you know where to look for a solution.
Some patterns are domain-specific e.g. patterns for distributed applications, some are created in-house e.g. patterns in the company/project and some can be self-created e.g. from past experience.
Be careful not to overuse patterns. Do not throw patterns at a problem at every opportunity. Patterns come with overhead such as adding more classes or increasing the levels of abstraction. Use them only when they are needed. Before applying a pattern, make sure that:
- there is substantial improvement in the design, not just superficial.
- the associated tradeoffs are carefully considered. There are times when a design pattern is not appropriate (or an overkill).
Evidence:
Take an example patterns in the project and explain its benefits and costs.
W12.2d Can explain how patterns exist beyond
software design domain
Design → Design Patterns →
Other Types of Patterns
The notion of capturing design ideas as "patterns" is usually attributed to Christopher Alexander. He is a building architect noted for his theories about design. His book Timeless way of building talks about "design patterns" for constructing buildings.
Here is a sample pattern from that book:
When a room has a window with a view, the window becomes a focal point: people are attracted to the window and want to look through it. The furniture in the room creates a second focal point: everyone is attracted toward whatever point the furniture aims them at (usually the center of the room or a TV). This makes people feel uncomfortable. They want to look out the window, and toward the other focus at the same time. If you rearrange the furniture, so that its focal point becomes the window, then everyone will suddenly notice that the room is much more “comfortable”
Apparently, patterns and anti-patterns are found in the field of building architecture. This is because they are general concepts applicable to any domain, not just software design. In software engineering, there are many general types of patterns: Analysis patterns, Design patterns, Testing patterns, Architectural patterns, Project management patterns, and so on.
In fact, the abstraction occurrence pattern is more of an analysis pattern than a design pattern, while MVC is more of an architectural pattern.
New patterns can be created too. If a common problem needs to be solved frequently that leads to a non-obvious and better solution, it can be formulated as a pattern so that it can be reused by others. However, don’t reinvent the wheel; the pattern might already exist.
Here are some common elements of a design pattern: Name, Context, Problem, Solution, Anti-patterns (optional), Consequences (optional), other useful information (optional).
Using similar elements, describe a pattern that is not a design pattern. It must be a pattern you have noticed, not a pattern already documented by others. You may also give a pattern not related to software.
Some examples:
- A pattern for testing textual UIs.
- A pattern for striking a good bargain at a mall such as Sim-Lim Square.
Evidence:
Give example patterns from other domains.
W12.5 Can describe a technical contribution
Covered by:
Slides: Will be uploaded after the lecture